Grundlagen
Die Juhuuu! Suche ist eine Volltextsuche, die nach einem oder mehreren Stichwörtern zeitgleich auf dem gesamten Datenbestand sucht. Die einzige Voraussetzung hierfür ist, dass die Daten vorher indiziert worden sind. Die Volltextsuche wird dann eingesetzt, wenn die Entität oder wesentliche Informationen zu dem gesuchten Datensatz nicht bekannt sind. Funktionalität und Handling sind mit Internetsuchmaschinen wie z.B. Google vergleichbar.
Diese Suche leistet besonders dann wertvolle Dienste, wenn selten vorkommende Suchbegriffe eingegeben werden können. In diesen Fällen liefert sie überschaubare Antwortmengen. Außerdem wird sie oft eingesetzt, wenn die Entität oder wesentliche Informationen zu dem gesuchten Datensatz nicht bekannt sind.
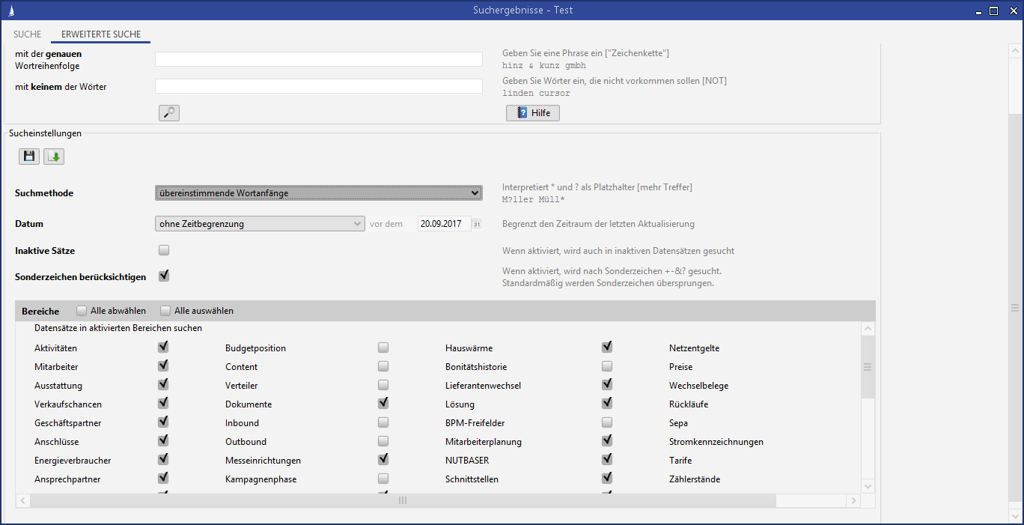
Für den Anwender präsentiert sich die Juhuuu! Suche im Applikationsfenster oben links und kann über die Schaltfläche 🔎 bzw. bei vorheriger Eingabe eines Stichwortes in das vorstehende Feld gestartet werden.

Mit dem Start der Suche wird das Fenster der Volltextsuche geöffnet und darin eine Liste der Suchergebnisse angezeigt. Ist kein Suchbegriff eingegeben, wird das Fenster der Volltextsuche geöffnet und man kann dort Suchbegriffe eingeben. Alle eingegebenen Stichwörter werden grundsätzlich mit einem logischen UND verknüpft. Das Ergebnis der Suche wird in einem eigenen Programmfenster angezeigt. Nach dem Aufruf eines Suchergebnisses können Sie über einen Taskwechsel (Tastenkombination Alt + ↔ Tab) wieder zurück in die Volltextsuche wechseln und einen weiteren Datensatz aufrufen. Auf der Lasche Erweiterte Suche stehen zusätzliche Optionen für die Ausführung der Suche zur Verfügung. Hier können Sie die Suche z.B. auf bestimmte Entitäten einschränken.
Administration
In diesem Knoten wird das Verhalten der Juhuuu!-Suche systemweit eingestellt. Jeder Administrator bekommt dieses als Voreinstellung angeboten und kann dann Änderungen vornehmen.
Die Voraussetzung für die Aufnahme einer Entität in den Juhuuu!-Index ist die Freigabe im Knoten Entitätenkonfiguration bearbeiten. Hierfür muss die Entität in der Spalte Juhuuu indiziert aktiviert werden. Die Auswahl muss für jede Entität separat bestätigt werden, um Fehlkonfigurationen zu vermeiden.
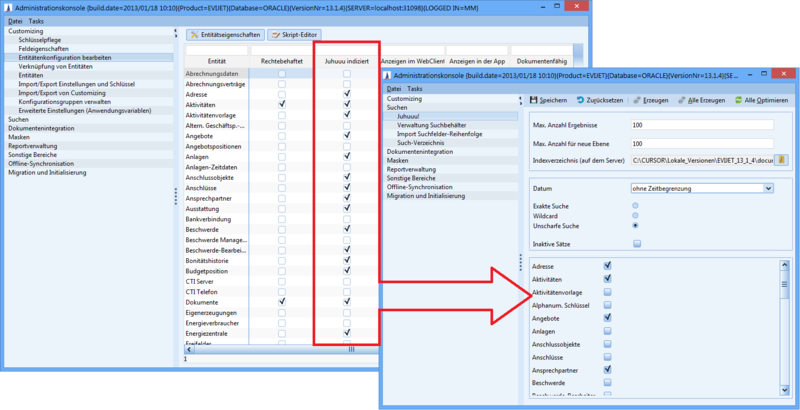
Abbildung: Entitätenkonfiguration Bearbeiten, Spalte: 'Juhuuu indiziert'
Nach dem Neustart des Clients werden die im Knoten Juhuuu! aktivierten Entitäten in der Liste angezeigt.
Dialogfenster
|
Max. Anzahl Ergebnisse |
Stellt die maximale Anzahl der angezeigten Treffen ein. |
|
Max. Anzahl für neue Ebene |
Zusätzlich können mehrere Suchergebniseinträge einer Entität in eine neue Ebene geladen werden. Der Defaultwert ist 100. Die maximale Anzahl für eine neue Ebene kann nicht größer als die maximale Anzahl der Ergebnisse der Juhuuu! Suche sein. |
|
Indexverzeichnis |
Hier wird das Serververzeichnis (auf dem Applikationsserver) eingestellt, in welchem der Spezielle Index für die Juhuuu! Suche abgelegt wird. Es handelt sich hierbei NICHT um eine Netzwerkfreigabe für die verbundenen Clients. |
|
Datum |
In dieser Auswahlliste stehen Optionen zur Verfügung, die die Datenmenge nach der Erfassungszeit einschränken können. (z.B. ohne Zeitbegrenzung, im letzten Monat etc.) |
|
exakt übereinstimmend
|
Ist dieser Parameter aktiviert, so werden nur genau übereinstimmende Ergebnisse bei der Suche ausgegeben. Groß-/Kleinschreibung wird ignoriert. |
|
Übereinstimmende Wortanfänge
|
Aktiviert bzw. Deaktiviert die Verwendungsmöglichkeit von Suchplatzhaltern in der Schnellsuche. Das Feld 'Suche nach Wildcard-Zeichen ermöglichen' wird beim öffnen der Maske aktiviert, diese Einstellung wird nicht gespeichert. Die Einstellung wirkt sich auf die Eingaben in der Lasche 'Erweiterte Suche' aus. Wird die Suche von dieser Seite gestartet, so werden die Wildcard-Zeichen "escaped", so dass nach ihnen gesucht werden kann. Wird dieses Kontrollkästchen deaktiviert, so werden die Wildcard-Zeichen bei der Suche berücksichtigt. Beim Wechsel auf die Lasche 'Suche' werden diese Zeichen ebenfalls "escaped". Eingaben auf der Lasche "Suche" werden immer in das Feld "Ergebnisse finden mit allen Wörtern" geschrieben. Das hat zur Folge, dass Änderungen auf dieser Lasche nicht auf der "Erweiterte Suche"-Lasche aufgeteilt werden. Wurden beim Wechsel zwischen diesen Laschen keine Änderungen vorgenommen, so bleibt die Zuordnung erhalten. |
|
unscharf übereinstimmend
|
Ist dieser Parameter aktiviert, so werden auch ähnliche geschriebene Ergebnisse bei der Suche ausgegeben. So wird z.B. ebenfalls der Name Mayer gefunden, wenn nach Meyer gesucht wurde. Je größer die Abweichung des Wortes, desto weiter unten wird es in der Ergebnisliste positioniert. Es handelt sich hierbei nicht um eine 'phonetische' Unterscheidung. Wird nach dem Wort 'Meyer' gesucht, so werden die Ergebnisse 'Mayer' und 'Leyer' als gleichwertig angesehen |
|
intelligente
|
kombiniert die unscharfe Suche und Suche mit den übereinstimmenden Suchanfängen |
|
Inaktive Sätze |
Über dieses Feld können als INAKTIV markierte Datensätze in das Suchergebnis mit einbezogen werden. |
|
Entitätenliste |
Die Entitätenliste in diesem Dialogfenster wird für 2 Aktionen genutzt:
Hier wird eingestellt, welche Entitäten standardmäßig berücksichtigt werden. Diese Vorbelegung wirkt sich ausschließlich bei Benutzern aus, die keine individuelle Einstellung gespeichert haben. 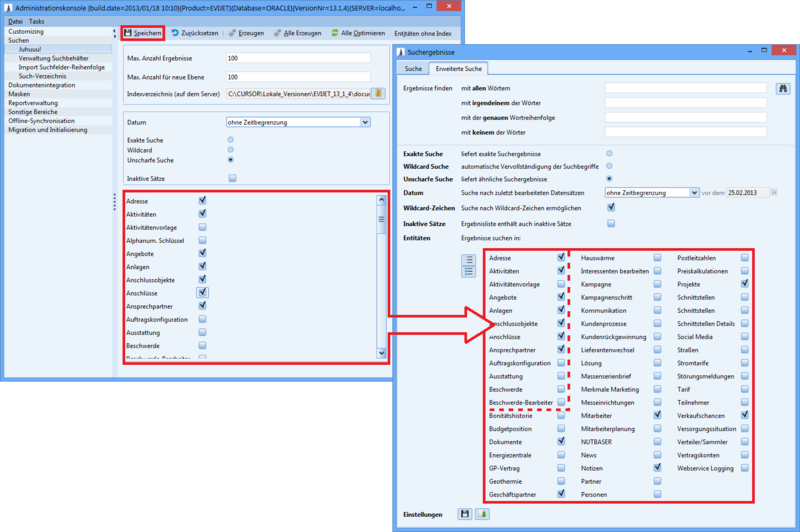
Hier wird eingestellt, für welche Entitäten der Index neu erstellt werden soll. Haben Sie z.B. eine C2Entität für die Indexierung freigeschaltet (Knoten Entitätenkonfiguration bearbeiten), können Sie nur um diese Entität den Suchindex erweitern. Hierfür aktivieren Sie in dem Dialogfenster nur die neu zu indexierende Entität und klicken auf den Schalter Erzeugen. Diese Änderungen an dieser Stelle haben unmittelbare Konsequenzen für die Suchergebnisse. Je mehr Objekte in den Index mit einbezogen werden, desto mehr Platz benötigt die Indexdatei. Je weniger Objekte indiziert werden, umso weniger erfolgreich wird die Schnellsuche, da dann viele Bereiche nicht mehr durchsucht werden. |
|
|
wählt alle Entitäten aus |
|
|
wählt alle Entitäten ab |
|
|
Mit einem Klick auf den Schalter speichern Sie die aktuellen sichtbaren Einstellungen auf der Maske. |
|
|
setzt die Einstellung auf die zuletzt gespeicherte zurück |
Schalterleiste
|
|
Es können die eingestellten Parameter in einer Datei gespeichert werden. |
|
|
Es können die aktuell auf der Maske gemachten Änderungen rückgängig gemacht werden. |
|
|
Es können die voreingestellten Parameter aus einer Datei geladen werden ( z.B. aus einer anderen CURSOR-CRM/EVI Version). |
|
|
Sind alle Optionen eingestellt, wird durch Klicken auf den Schalter die Indexdatei für die Volltextsuche erstellt. |
|
|
Bewirkt, dass für alle Entitäten eine Indexdatei erstellt wird. |
|
|
Es wird eine Optimierung der Suche ausgeführt Tipp Um z.B. nach einer Migration den gesamten Datenbestand erstmalig zu indizieren, müssen Sie wie folgt vorgehen:
Der Indexierungsprozess startet und dauert je nach Datenbestand einige Stunden lang. Es wird empfohlen, den Prozess abends oder am Wochenende zu starten, damit der Produktivbetrieb nicht unter dem Prozess leidet. |
|
Entitäten ohne Index |
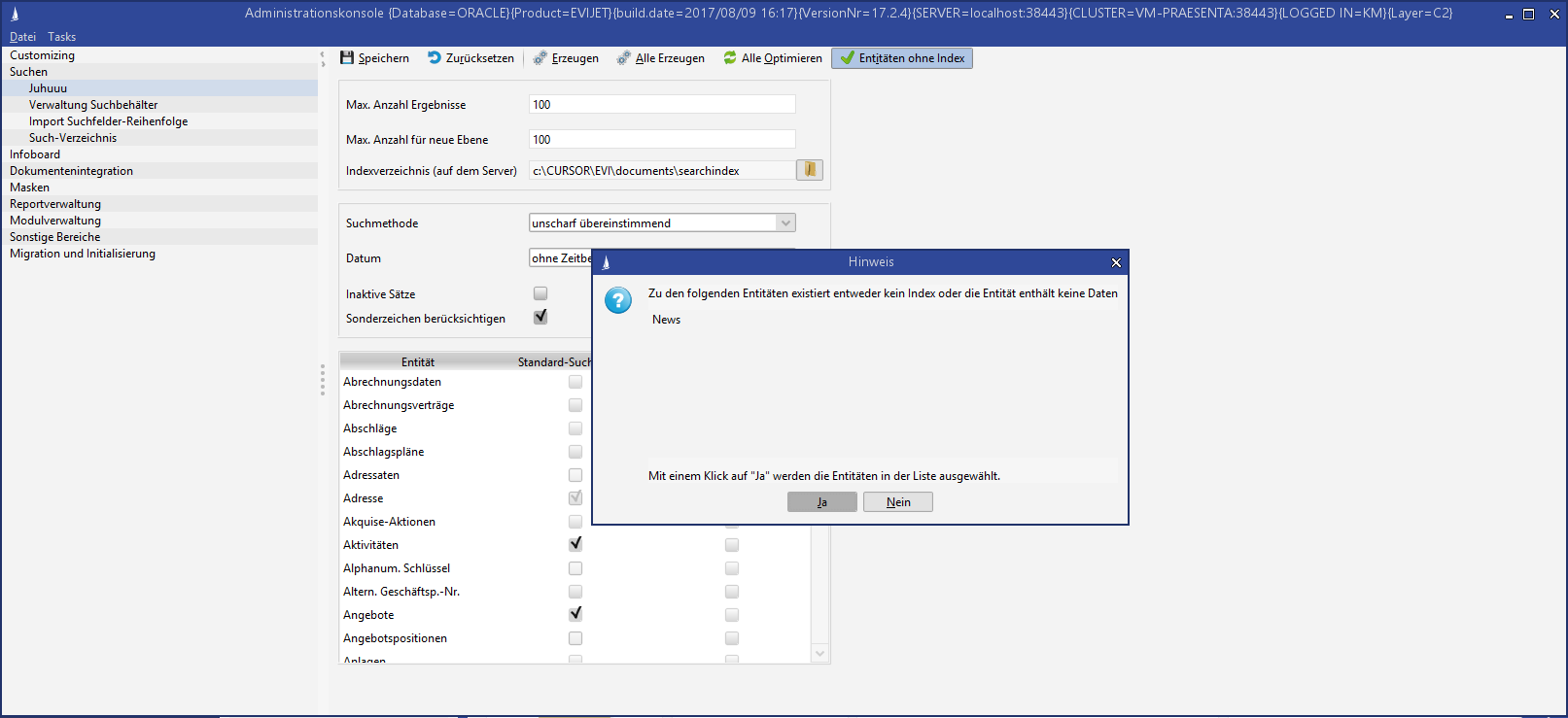
Es kann vorkommen, dass für eine Entität kein Index existiert, obwohl die Entität für die Indexierung aktiviert wurde. Sei es ein Fehler bei der Indexgenerierung oder die Entität enthält keine Daten (z.B. eine leere neu angelegte C2-Entität). Mit einem Klick auf den Schalter können Sie diese Entitäten identifizieren. In dem darauffolgenden Dialog können Sie die Entitäten für die erneute Indexierung übernehmen. So gehen Sie vor:
|
Logik der Entitäten-Indexierung
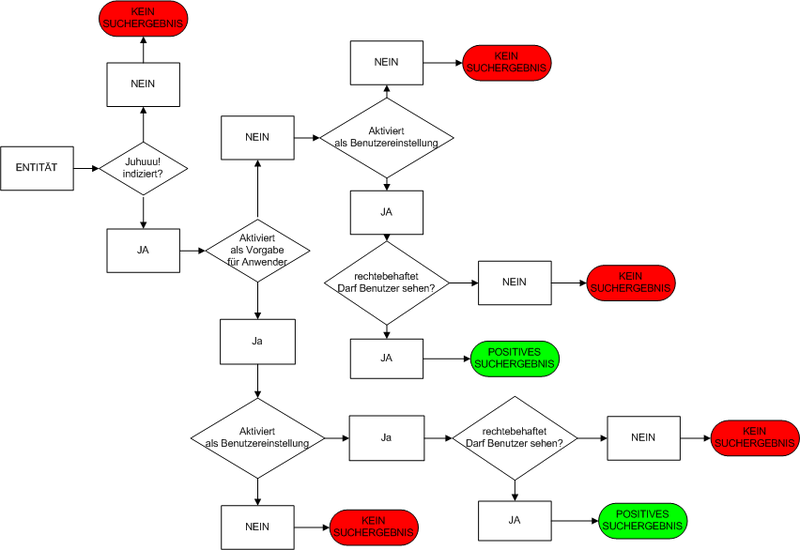
Fazit
Damit Suchergebnisse positiv sind, müssen folgende Voraussetzungen erfüllt sein:
-
die Entität muss für die Indizierung aktiviert sein
-
die Entität muss in den Konfigurationseinstellungen aktiviert sein
-
der Anwender muss über entsprechende Rechte verfügen (Recht die Entität und den Datensatz zu sehen)
Der Index wird für alle explizit aktivierten Entitäten erstellt. Erst im letzten Schritt wird geprüft, ob der Anwender, der die Suche ausführt, das Recht hat, die Entität und den Datensatz zu sehen.
Auswirkung der Logik im Web Client
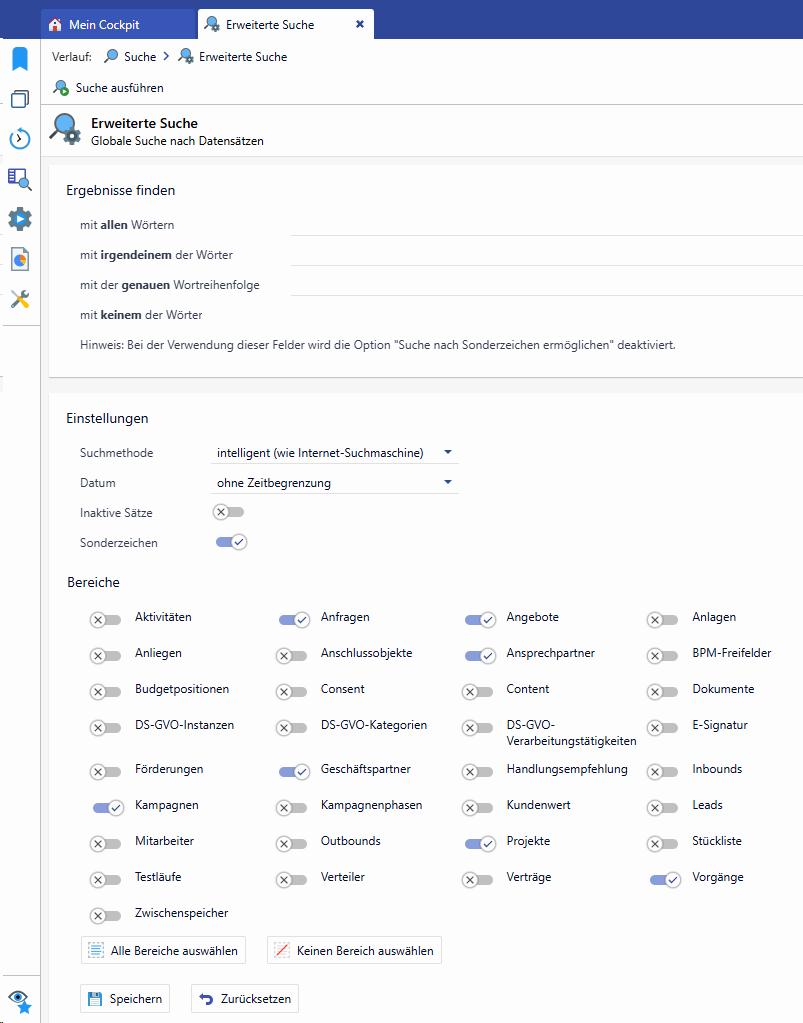
Derselbe Index wird auch im Web Client genutzt. Werden über den Windows Client mehrere Entitäten indiziert, stehen die Daten zum Abruf bereit. Unter Web Client müssen genau dieselben Bedingungen erfüllt sein, damit Datensätze gefunden werden:
-
die Entität muss für die Indizierung aktiviert sein
-
die Entität muss in den Konfigurationseinstellungen aktiviert sein
-
der Anwender muss über entsprechende Rechte verfügen (Recht die Entität und den Datensatz zu sehen)
Damit die Entität in den Konfigurationseinstellungen aktiviert werden kann, muss die Entität im Knoten Entitätenkonfiguration bearbeiten für den Web Client freigeschaltet werden. Wird sie es nicht, so wird die Entität in den Konfigurationseinstellungen nicht angezeigt und kann nicht bei der Suche berücksichtigt werden.
Konfiguration der Vorschlagslisten
Die Lookup-Vorschlagsliste wird durch die Lucene-Suche generiert. Lucene kann nicht nach „enthält“ suchen. Auf die Reihenfolge der Suchergebnisse wird bewusst kein Einfluss genommen, da die Reihenfolge nach der Lucene-Gewichtung (dem sogenannten Score) verwendet wird. Würden die Ergebnisse sortiert, würde dies in einer sehr inperformanten Antwortzeit bei größeren Datenmengen resultieren, da dann zunächst das Suchergebnis komplett aufgebaut und sortiert werden müsste.
Die Lookup Vorschlagsliste sucht auf dem Feld LookupContent des LuceneIndex, dessen Inhalt über die Konfiguration Juhuuu! Nachschlageindexfelder in den Entitätseigenschaften vorgenommen werden kann.
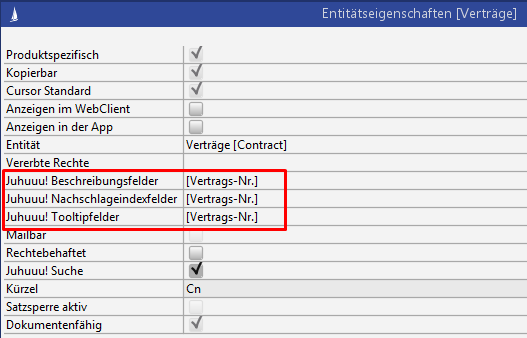
Abbildung: Konfiguration der Nachschlageindexfelder
Beispiel: im Auslieferungszustand ist das Feld Vertragsstatus enthalten. Mit dieser Konfiguration werden nur noch die Nummern gefunden:
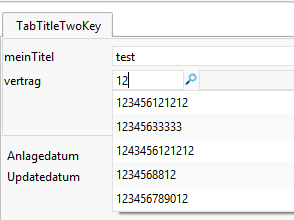
Im System enthalten waren die Nummern:
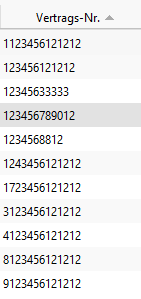
Enthält die Vertragsnummer allerdings ein "Whitespace" wie z. B. den Underscore, so werden auch diese Ergebnisse gefunden.
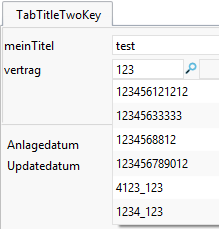
Bei den Vertragsnummern:
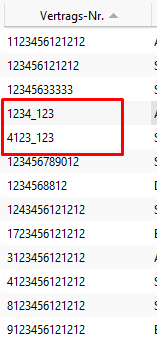
Ergebnismenge in Liste übertragen
In der Juhuuu!-Suchmaske kann der Anwender jeweils einen Suchergebniseintrag in einer neuen Ebene öffnen. Dies erfolgt per Mausklick auf dem Suchergebniseintrag. Zusätzlich können auch mehrere Suchergebniseinträge einer Entität in eine neue Ebene geladen werden.
Laden der Daten per Kontextmenü im Suchergebniseintrag
Per rechten Mausklick auf einem Suchergebniseintrag öffnet sich ein Kontextmenü mit der Möglichkeit, aus der Suchergebnismenge mehrere Einträge dieser Entität direkt in eine neue Ebene zu laden. Die Einschränkung der Menge (hier 100) kann in der Administrationskonsole konfiguriert werden.
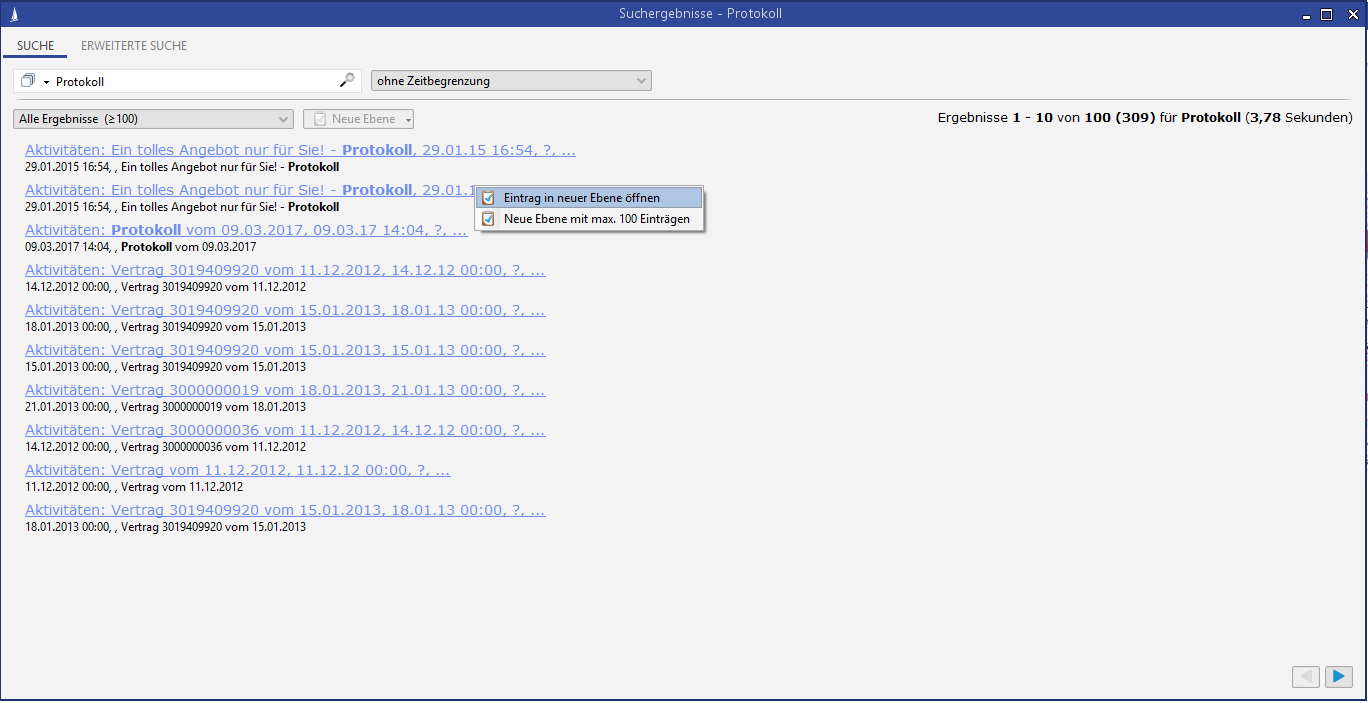
Abbildung: Beispiel für Kontextmenü zum Suchergebniseintrag
Laden der Daten per Neue-Ebene-Schalter
Neben dem Auswahlfeld für Entitäten befindet sich der Schalter Neue Ebene. Dieser ermöglicht das Laden der Suchergebnismenge einer Entität in eine neue Ebene. Per einfachen Klick auf dem Schalter wird eine empfohlene Anzahl von Suchergebniseinträgen in die neue Ebene geladen. Dieser Wert kann in der Administration der Juhuuu! Suche konfiguriert werden.
Möchte man noch mehr Suchergebniseinträge in die neue Ebene laden, so kann dies über das Kontextmenü erreicht werden.
-
Die Standardaktion des Schalters entspricht immer dem ersten Eintrag im Kontextmenü
-
Der Schalter wird aktiv, sobald in der Auswahlbox eine Entität ausgewählt wurde.
-
Die maximale Suchergebnisgröße für eine neue Ebene entspricht der maximalen Größe des Suchergebnisses der Juhuuu! Suche. Die Konfiguration der maximalen Größe des Suchergebnisses der Juhuuu! Suche erfolgt in der Administrationskonsole.
Indizierung
Datenformate
Die Volltextsuche indiziert neben den in der Adminstrationskonsole konfigurierbaren Entitäten auch die in der Applikation abgelegten Dokumente mit Dokumentenart INTERN. Dies umfasst die aus CURSOR-CRM heraus erstellten Dokumente (z.B. Einzelbrief) ebenso wie die importieren Dokumente (z.B. per Drag&Drop). Ausgeschlossen sind nur Dokumente, die als Links hinterlegt sind (beispielsweise in einem Archiv). Die Indizierung wird für Dateien mit den Dateitypen: xls, xlsx, ppt, pptx, doc, docx, dot, dotx,xlsm, dotm, docm, pptm, pdf, txt, htm, html und rtf durchgeführt, wobei nur textbasierte Dokumente indiziert werden (z.B. keine gescannten PDF-Dateien).
Tipp
Überprüfen Sie Ihren PDF-Treiber, ob ein textbasiertes PDF-Dokument generiert wird.
Verschlüsselte PDF-Dokumente
Die Indizierung von verschlüsselten internen PDF-Dokumenten kann über die folgenden PropertyMapper-Einträge gesteuert werden:
Setzen des globalen Passworts, das auch zur Verschlüsselung von PDF-Dokumenten verwendet wird (dieses Passwort muss im Tool zur Erstellung der PDFs verwendet werden):
id 'SYSTEM_NODE:/de/cursor/jevi/server/system/search/simplesearch/documents/handler/PDFBoxPDFHandler$!!$GeneralPdfPassword'
propertyType 'SYSTEM'
propertyValue 'meinPasswort'
Soll diese Funktionalität nicht verwendet werden, kann dies mit dem folgenden Eintrag deaktiviert werden:
id 'SYSTEM_NODE:/de/cursor/jevi/server/system/search/simplesearch/documents/handler/PDFBoxPDFHandler$!!$TryPdfDecryption'
propertyType 'SYSTEM'
propertyValue 'false'
Nutzen:
PDF-Dateien, die verschlüsselt an Kunden versendet werden müssen, können nun mit der Lucene Suche indiziert werden.
Wartung
Ist die Indizierung einmalig erfolgt, so ist die Juhuuu! Suche einsatzbereit. Alle Änderungen an Daten bzw. alle Neuanlagen werden automatisch in den Index aufgenommen. Um ein optimales Suchergebnis zu gewährleisten, wird empfohlen, einmal im Monat eine Optimierung des Indexes durchzuführen. Dieser Prozess dauert nur wenige Minuten. Hierbei werden mehrere Indizes zusammengefasst und gelöschte Daten aus dem Index entfernt. Durch technische Gegebenheiten, wie zum Beispiel paralleles Bearbeiten von Daten durch mehrere Nutzer, kann es sehr selten vorkommen, dass Änderungen nicht in den Index aufgenommen werden können. Um die Menge möglichst zu minimieren können Sie von Zeit zu Zeit die vollständige Indexierung starten.
Sollte die Automatisierung und die Optimierung der Indizes automatisch erfolgen und der Verwaltungsaufwand minimiert werden, ist Kontakt mit CURSOR Software AG erforderlich.
Stop-Words
Stop-Words
Stop-Words sind einfache Füllwörter, die bei einer Suche auf großen Daten keine Vorteile bringen, deshalb werden sie ausgeschlossen, um den Index klein zu halten.
-
Im Standard wird keine Stop-Wort-Liste genutzt
-
Über den PropertyMapper ist konfigurierbar, welche Stop-Worte genutzt werden können
-
ID='/de/cursor/jevi/common/lucene/AnalyzerFactory$!!$StopWords'
können mit dem Trenner
$!!$Stop-Worte hinterlegt werden (CN-Schicht) -
Wird in diesen PropertyMapper-Eintrag der Wert
getDefaultStopSet()hinterlegt, so wird der vorherige Standard genutzt.
-
Nach den Änderungen ist ein Serverneustart und Neuindizierung notwendig.
-
Stop-Words für die deutsche Sprache
Stop-Words-Liste:
"als", "am", "auf", "aus", "das", "dass", "daß", "der", "dich", "die", "dir", "du", "durch", "eine", "einem", "einen", "einer", "eines", "er", "es", "für", "ihr", "ihre", "ihres", "im", "in", "ist", "kein", "mein", "mich", "mir", "mit", "oder", "ohne", "sein", "sie", "und", "von", "war", "was", "wegen", "wer", "wie", "wir", "wird"
Hinterlegen einer Liste von Sprachen für die Juhuuu-Indizierung
Die Liste der Sprachen für die Juhuuu-Indizierung wird in der Anwendungsvariable
/de/cursor/jevi/server/system/search/simplesearch/IndexHandler$!!$IndexLanguages definiert.
Gültige Werte sind:
|
Wert |
Sprache |
|---|---|
|
en |
Englisch |
|
de |
Deutsch |
|
fr |
Französisch |
|
it |
Italienisch |
|
sl |
Slovenisch |
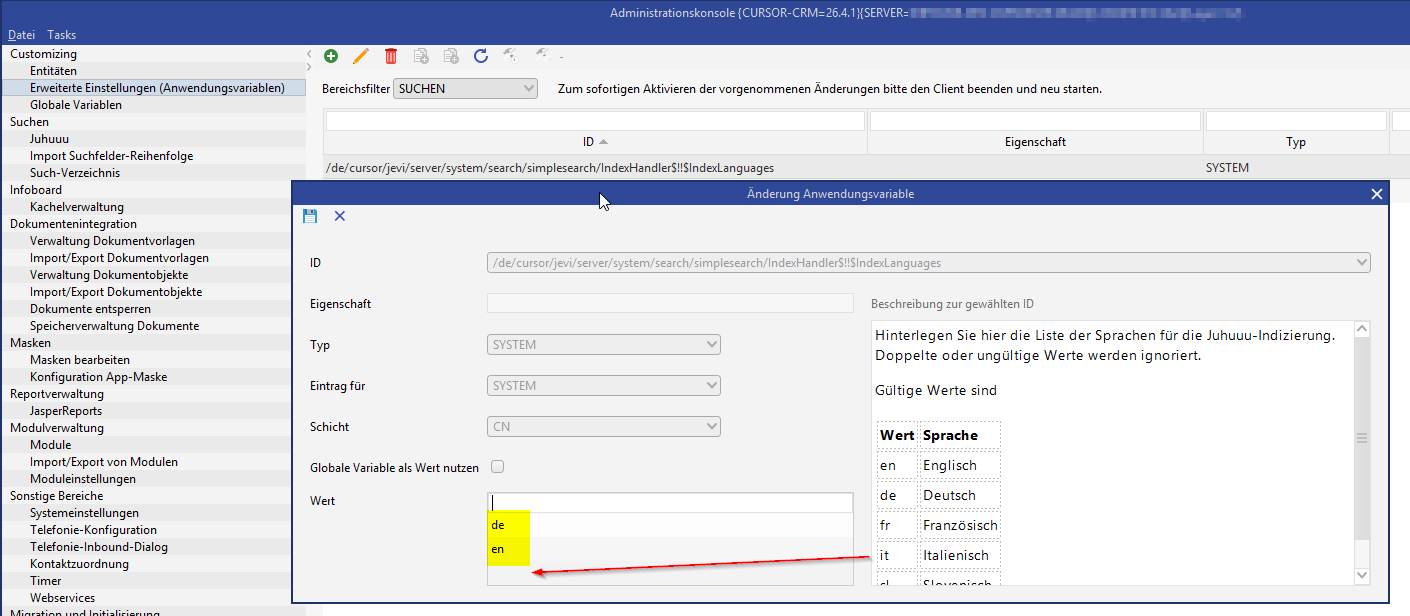
Im Standard ist diese Variable nicht ausgeliefert und wird mit dem Standard-Locale des Servers vorbelegt (das kann z. B. 'de' oder 'en' sein). Diese Einstellung wird aus der Umgebung des Servers gelesen oder kann in der standalone.conf.bat (Windows) bzw. standalone.conf (Linux) explizit gesetzt werden (SET LANGUAGE=de, bzw. export LANGUAGE=de).
So wird sichergestellt, dass die definierte Sprache der Anwendung indiziert ist.
Soll der Index eine oder mehrere weitere Sprachen unterstützen, kann diese Anwendungsvariable angelegt und die fünf unterstützten Sprachen hinterlegt werden.
Wird eine nicht unterstützte Sprache hinterlegt, wird sie ignoriert und ein Protokolleintrag ausgegeben.
Wird eine nicht Sprache mehrfach hinterlegt, wird sie nur einmal genutzt und ein Protokolleintrag ausgegeben.
Ist die Standard-Sprache des Servers nicht hinterlegt, so wird sie noch hinzugefügt.
Ist z. B. 'de' und 'en' eingetragen, so werden zwei Lucene-Index-Verzeichnisse erstellt, in einem sind die Einträge für 'de', in dem anderen die Einträge für 'en' enthalten.
Auch im tmp-Bereich, der zum parallelen Aufbau eines neuen Index genutzt wird, sind dann beide Sprachen zu finden.
Bereichsranking für die COMMAND Suchergebnisse
Das Ranking der unterschiedlichen Bereiche kann über eine Konfigurationseinstellung verändert werden, so dass man einzelne Bereiche höher gewichten kann und damit die Treffer aus diesem Bereich weiter oben angezeigt werden.
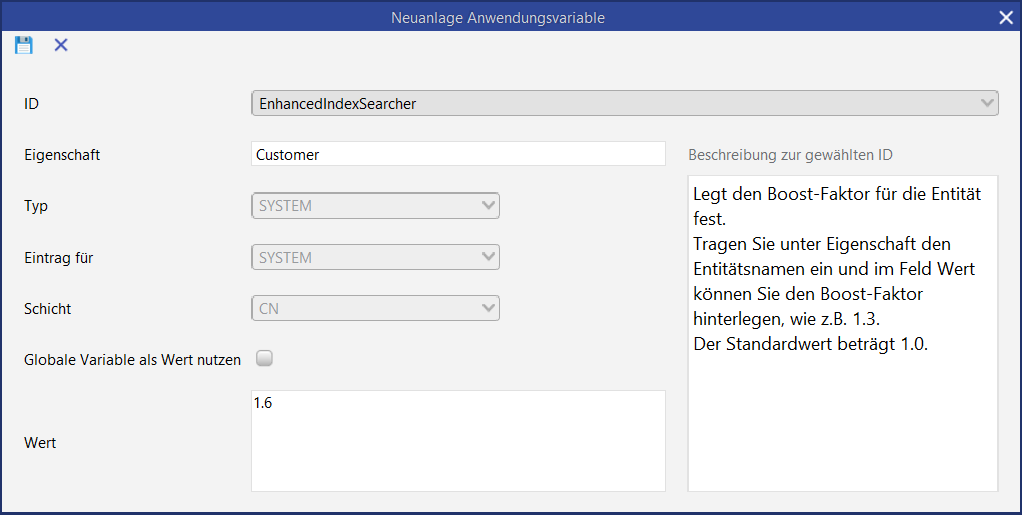
Abbildung: Konfiguration der Gewichtung
In der Anwendungsvariable EnhancedIndexSearcher kann die Gewichtung für Bereiche konfiguriert werden.
Die Gewichtung erfolgt prinzipiell nach folgender Logik:
-
Wenn kein Eintrag für einen Bereich vorhanden ist der Score 1.0
-
Alles unter 1.0 wertet den Bereich ab
-
Alles über 1.0 wertet den Bereich auf
Folgende Scoring-Einstellungen werden ausgeliefert:
-
Geschäftspartner: 1.5
-
Ansprechpartner: 1.3
-
Mitarbeiter: 1.2
-
Aktivität: 0.25
-
Dokumente: 0.1
-
Projekte: 0.25
-
Vorgang: 0.25
Juhuuu!-Suchfeld in der Standardsuchmaske
Ein Juhuuu!-Suchfeld kann über die Lasche 'Suche bearbeiten' konfiguriert und hinzugefügt werden. Somit können Vorteile einer textbasierten Suche, die nach einem oder mehreren Stichwörtern zeitgleich auf dem definierten Datenbestand (im Beispiel: Entität 'Mitarbeiter') sucht, mit der Suche auf bestimmten Feldern kombiniert werden.
Ein weiterer Vorteil besteht darin, dass mehrere Suchkriterien in nur ein Juhuuu! Suchfeld eingegeben werden können, ohne die Einträge in die übrigen Suchfelder vornehmen zu müssen.
-
Sie Suchen nach einem Mitarbeiter mit dem Kürzel XYZ aus der Abteilung 'Produktmanagement'
Eingabe: XYZ Produktmanagement -
Welcher Kollege hat die Telefonnummer 803?
Eingabe: 803 -
Wer ist Abteilungsleiter Entwicklung?
Eingabe: Leiter Entwicklung
Da Sie mehrere Suchkriterien über ein Juhuuu!-Suchfeld definieren können, benötigen Sie für die Standard-Suchmaske deutlich weniger Suchelder.
Wildcard-Suche
Sollte eine Wildcard-Suche ausgewählt werden, so werden die Wildcards implizit angewendet und sollten nicht vom Anwender gesetzt werden. Es handelt sich in diesem Fall um eine Teilstring-Suche.
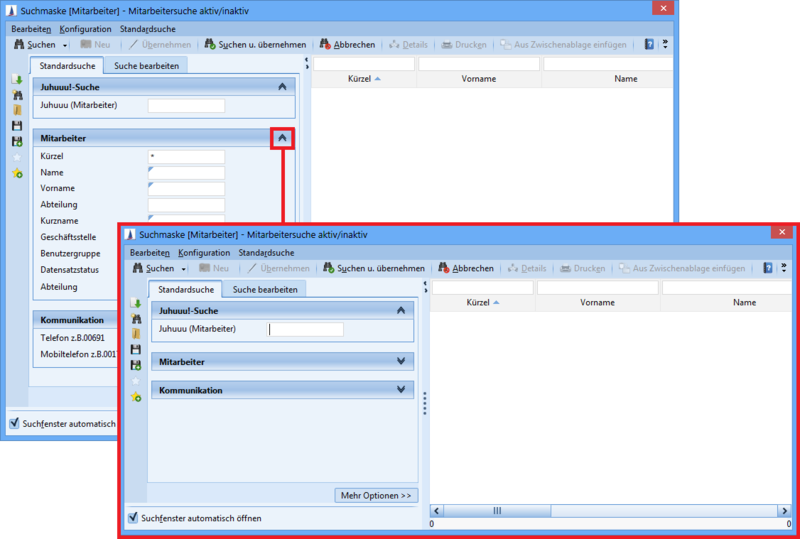
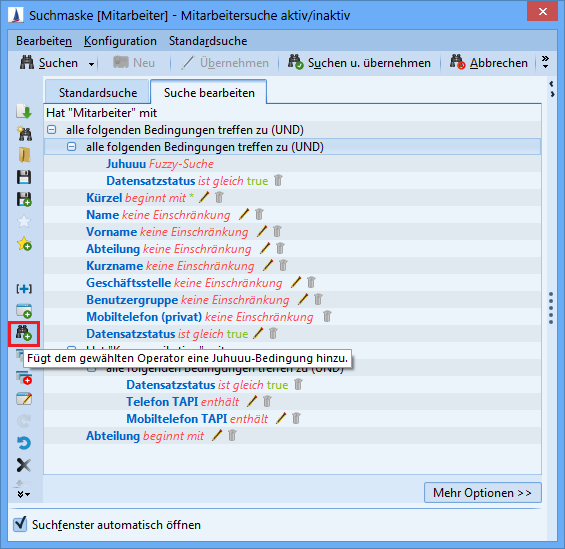
Das Hinzufügen unterliegt dabei den folgenden Einschränkungen:
-
Das Feld kann nur zu Operator-Knoten hinzugefügt werden (z.B. "alle folgenden Bedingungen treffen zu (UND)").
-
Es kann nur ein Feld pro Operator-Zweig (Entität) hinzugefügt werden.
-
Die Entität auf der das Feld hinzugefügt werden soll, muss dem Juhuuu!-Index hinzugefügt sein.
Fuzzy-Suchen (unscharfe Suchen) können die Performance des Systems beeinflussen.
Neuaufbau des Suchindex für die von einer Schnittstelle aktualisierten Tabellen
Strukturänderungen der Tabelle UnindexedEntity
-
Neues Feld Priority vom Typ INTEGER
-
Funktion
In diesem Feld wird die Priorität eines zu indizierenden Datensatzes hinterlegt. Über CURSOR-CRM wird nur die Priorität 1 in diese Spalte eingetragen.
Eine Schnittstelle kann dieses Feld mit 2 füllen, dann werden diese Datensätze nachgelagert indiziert. Dieses Vorgehen ist bei Änderungen ab 10000 bis zu 100000 Sätzen sinnvoll, wenn der Timer zur Indizierung mit dem Standardwert von 15 Minuten konfiguriert ist. -
Beispiel
Es wurden 100000 Datensätze in die UnindexedEntity aufgenommen. Die Einträge in der UnindexedEntity werden in 10000er Blöcken abgearbeitet.
Bei dieser Konfiguration sind mindestens 10 Durchgänge notwendig, um alle Daten zu indizieren, da ja noch über die Anwendung Datensätze hinzu kommen. Die in der Anwendung angelegten Datensätze werden nun immer am Anfange eines solchen Blocks bearbeitet. Es dauert also ca. 150 - 165 min bis alle eingetragenen Daten indiziert wurden.
Für die Version 13.2 wurde diese Funktionalität zurückgepatcht, allerdings wurde dort das Feld "ClientNo" für diese Funktionalität verwendet.
-
-
Neues Feld IndexedStatus NUMBER (1)
-
Funktion
In diesem Feld markiert die Anwendung die Datensätze, die sie bereits versucht bzw. versuchte zu indizieren.
Hintergrund ist das Problem von Excel-Dateien, die während der Indizierung im Speicher geladen und gelesen werden. Diese können im Speicher so groß werden, dass die Anwendung auf eine OutOfMemoryException stößt und der Sever durchgestartet wird. Durch diese Markierung läuft der Server dann nicht erneut auf dieses Problem, da er nur nicht markierte Daten indiziert.
In Vorgängerversionen wurde hierfür das Feld "Status" missbraucht.
-
Neuaufbau des Juhuuu-Suchindex über UnindexedEntity
Die Schnittstelle kann in die Tabelle UnindexedEntity einen Datensatz eintragen, der das Neuindizieren einer Entität auslöst.
Dieser Datensatz muss wie folgt gefüllt sein:
-
Pk = Entitätsname
-
EntityName = Entitätsname
-
TableTail ist zu füllen
Wird bei einem Lauf über die UnindexedEntity ein solcher Datensatz gefunden, so wird die gesamte Entität neu indiziert.
Vorteil:
Es müssen nicht alle geänderten Datensätze einzeln in die UnindexedEntity geschrieben werden.
Nachteil:
Die Laufzeit zum Neuaufbau eines Indexes kann recht hoch sein. In dieser Zeit kann kein anderer Index aktualisiert werden.
Neuaufbau eines Index in einem separaten Verzeichnis
Wird ein Index neu aufgebaut, so kann auf dem alten Stand weiter gelesen werden. Erst wenn der Index neu erstellt ist, wird dieser an den "Lesestandort" kopiert.
Der Neuaufbau erfolgt im Unterverzeichnis NEW des eigentlichen Suchindex-Verzeichnisses.
Abarbeitung der inkrementellen Juhuuu!-Indizierung ist konfigurierbar
Auf Servern mit einer geänderten Server-Einstellung für DEFAULT_MAX_ROW_NO=10000 kann nun die Blockgröße der inkrementellen Juhuuu!-Indizierung konfiguriert werden, da diese Einstellung in extremen Fällen zum Abbruch der Indizierung führen kann.
Die Blockgröße wurde vom Wert von DEFAULT_MAX_ROW_NO auf Standard 768 geändert.
Soll die Blockgröße auf z. B. 5000 geändert werden, kann dies mit dem folgenden PropertyMapper-Statement
ORACLE
INSERT into PropertyMapper (Pk, id, property, propertyType, principal,
CustLayer, propertyValue , Active, MassData,
RightPk, CreateUser, UpdateUser, CreateDate, UpdateDate) Values
('disableInstallationMaskLogic','/de/cursor/jevi/server/system/search/simplesearch/IndexHandler$!!$luceneIndexBlockSize',
null, 'SYSTEM', null, 'CN', '5000', 1, 0,
'RIGHTTEMPLATE', 'TECH_USER', 'TECH_USER', sysdate, sysdate)
MSSQL
INSERT into PropertyMapper (Pk, id, property, propertyType, principal,
CustLayer, propertyValue , Active, MassData,
RightPk, CreateUser, UpdateUser, CreateDate, UpdateDate) Values
('disableInstallationMaskLogic','/de/cursor/jevi/server/system/search/simplesearch/IndexHandler$!!$luceneIndexBlockSize',
null, 'SYSTEM', null, 'CN', '5000', 1, 0,
'RIGHTTEMPLATE', 'TECH_USER', 'TECH_USER', GETDATE(), GETDATE())
Ist der gesetzte Wert ungültig (kleiner 1 oder größer als die DEFAULT_MAX_ROW_NO oder auch keine Zahl), wird der Standardwert von 768 genutzt.
Lucene-Index kann auf einem Massendatenserver ausgelagert werden
Der Aufbau des Lucene-Index kann auf einen Report-Server verlagert werden. Die Konfiguration erfolgt über die Admin-Konsole.
-
Stabilität:
Der Indexaufbau kann beim Extrahieren von Text aus Dokumenten auf OutOfMemory laufen. Speziell beim Extrahieren von Text aus Excel-Dateien (die einzigen, die bisher Probleme verursachten), kann man nicht zuverlässig sagen, wieviel Speicherplatz eine bestimmte Datei zum Extrahieren von Text benötigt.
Wird die Operation auf einen anderen Server verlagert, wird dieser zwar ebenfalls mit OutOfMemory hängen bleiben, allerdings hat dies weniger dramatische Folgen auf die Arbeit der Anwender. -
Performance:
Der komplette Neuaufbau des Index benötigt nicht unerhebliche Ressourcen auf dem Applikationsserver. Durch eine Verlagerung auf den alternativen Anwendungsserver wird diese Last vom "Haupt-Server" genommen.
Annahmen/Voraussetzungen/Rahmenbedingungen
-
Es muss ein alternativer Anwendungsserver installiert und konfiguriert werden
-
Das Modul "Massendatenserver" muss aktiviert sein
-
Der Lucene-Index soll auf dem alternativen Anwendungsserver aufgebaut werden können, wenn es einen solchen im System gibt.
-
Ist kein alternativer Anwendungsserver konfiguriert, erfolgt die Indizierung auf dem Haupt-Server
Details zur Konfiguration
Ist ein alternativer Anwendungsserver konfiguriert und die Einstellung zur Nutzung aktiviert
-
Die initiale Indizierung startet auf dem alternativen Anwendungsserver
-
Die manuelle Indizierung von Entitäten startet auf dem alternativen Anwendungsserver
-
Die inkrementelle Indizierung startet auf dem alternativen Anwendungsserver
-
Der Index kann von allen anderen Servern im System gelesen werden
Wurde der alternativen Anwendungsserver neu gestartet, kann es vorkommen, dass ein Job gerade in Arbeit war und nun auf dem Status "PROCESSING" steht. Im Initialisierungstimer des alternativen Anwendungsservers soll deshalb der Status "PROCESSING" geprüft und zurückgesetzt werden, damit alle Jobs kontinuierlich abgearbeitet werden.
-
Der Initalisierungstimer wird auch auf dem alternativen Anwendungsserver ausgeführt
-
Dieser prüft aber nur nach noch laufenden Jobs
-
Diese Jobs werden im Status zurückgesetzt und die Ausführung wird neu gestartet.
Mitarbeiterabgleich löst Such-Index-Aktualisierung aus
Im Rahmen eines Mitarbeiterabgleichs in DEV- und QS-Systemen neu angelegte Mitarbeiter erscheinen im Such-Index. Nach dem Abgleich wird am Ende der Tabelle UnindexedEntity ein entsprechender Datensatz angelegt, damit das System anschließend den Such-Index aktualisiert.