Allgemeine Modellierung
Fachliches und technisches BPM-Modell verwenden dieselbe Sprache und Vorgehensweise für die Modellierung. Sie unterscheiden sich inhaltlich und in den Ausprägungen der verwendeten Elemente. Während im fachlichen Modell die Einfachheit und Dokumentation im Vordergrund steht, liegt der Fokus des technischen Modells auf der Ablauffähigkeit der Elemente und demzufolge auf korrekter Konfiguration und syntaktischer Korrektheit.
Im fachlichen Modell können Sie mehrere Pools modellieren. Im technischen Modell können Sie Details für genau einen Pool spezifizieren.
Modellierungsempfehlungen
Ziel von Modellierungsempfehlungen ist es, die Zusammenarbeit zwischen verschiedener Prozess Designern zu erleichtern, die Übersichtlichkeit und Verständlichkeit zu erhöhen und das Fehlerrisiko zu senken.
Allgemeine Best Practices
-
Praxisorientierte Reduktion der verwendeten Symbole zur Komplexitätsreduktion (Weniger ist mehr!)
-
Mut, Standardabläufe zu dokumentieren, nicht alle Ausnahmen!
-
Erfahrungen sammeln, also Prozesse iterativ verfeinern, also nicht alles auf einmal umsetzen…
-
Weitere Zusammenarbeitsmodelle wie Konversation und Choreographie erst einsetzen, wenn Prozessmodellierung vertraut ist
-
Unternehmensinterne Modellierungskonventionen definieren (ausreichend präzise, mit anschaulichen Beispielen)
-
So detailliert wie nötig und so übersichtlich wie möglich, d.h. im fachlichen Modell:
-
Standardabläufe modellieren,
-
Ausnahmen nur dokumentieren!
-
-
Es muss ein durchgehender Weg durch den Prozessfluss modelliert werden vom Start- bis zum Ende-Ereignis (das "Prozesstoken" muss durchfließen können)
Layout
-
Beschränkung auf "eine DIN A4-Seite“, bei Überschreiten prüfen Aufteilung durch Teilprozesse
-
Keine Überlagerung von Symbolen, insbesondere Sequenzflüssen
-
Sequenzflüsse laufen von links nach rechts und von oben nach unten
-
Aktionen haben genau 1 eingehenden und 1 ausgehenden Sequenzfluss
-
Sequenzflüsse knicken rechtwinklig ab
Namensgebung
-
Möglichst präzise Bezeichnungen
-
Eindeutige Bezeichnung für jedes Element
-
Prozesse: Nomen (z.B. Antragsbearbeitung)
-
Ereignisse: Objekt und Partizip Perfekt (z. B. Bedarf festgestellt)
-
Aktionen: Objekt und Verb (z.B. Antrag erfassen)
Prozessstruktur
-
Zuständigkeiten modellieren (Pools und Lanes)
-
Genau ein Start-Ereignis, mindestens ein Ende-Ereignis
-
Start-Ereignis: genau ein ausgehender Sequenzfluss
-
Ende-Ereignis: genau ein eingehender Sequenzfluss
-
Sendende Ereignisse = Aufgaben, empfangende Ereignisse = Nachrichten
-
Hierarchische Verwendung von Teilprozessen (kein Zirkelschluss)
-
Keine Zusammenführung oder Verzweigung durch Aktionen, nur durch Gateways
-
Gateways: entweder zusammenführen oder verzweigen
-
Verzweigende Gateways stellen Fragen dar, die zugehörigen Antworten befinden sich an den ausgehenden Sequenzflüssen
-
Jedes zusammenführende Gateway hat mindestens zwei eingehende Sequenzflüsse
-
Jedes verzweigende Gateway hat mindestens zwei ausgehende Sequenzflüsse
-
Jedes verzweigende Gateway hat genau einen ausgehenden Standardsequenzfluss
Benutzeroberfläche zur fachlichen und technischen Modellierung
Für die Modellierung steht Ihnen eine grafische Benutzeroberfläche zur Verfügung.
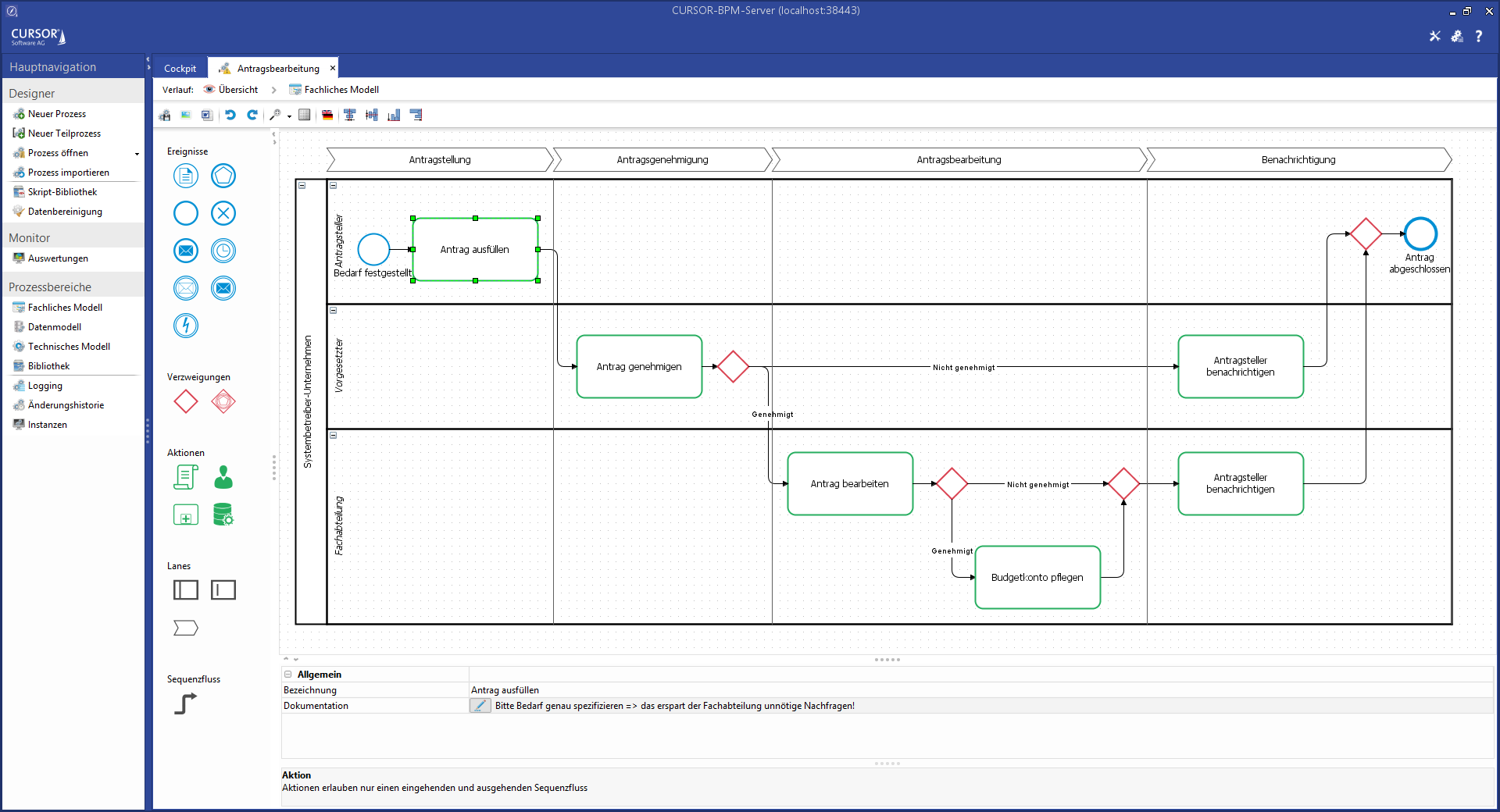
Links in der Palette sind alle verfügbaren Elemente aufgelistet. Die Elemente können mit der Maus per Drag and Drop auf die Zeichenfläche gezogen werden.
Die Position der unterteilten Bereiche von der Palette und den Zellen-Eigenschaften werden pro Modellart beim Verlassen der Ansicht gespeichert und beim nächsten Aufruf wieder geladen.
Allgemeine Bedienung und Verlauf
Die Bearbeitung von Elementen erfolgt über Drag and Drop oder mittels Editoren, wie beispielsweise im Falle der Dokumentation. Die Editoren nutzen den zur Verfügung stehenden Platz, um möglichst viele Informationen anzeigen zu können. Die Navigation erfolgt daher über die Zeile Verlauf. Sie können dort z. B. auf ![]()
Sie werden dann beim Navigieren gefragt, ob Sie speichern möchten. Durch Betätigen des Schalters Übernehmen können Sie die Änderungen (zwischen) speichern bzw. über den Schalter Übernehmen und Schließen direkt in das Modell zurückkehren. Das Speichern des Gesamtprozesses erfolgt durch Betätigen des Speicherbuttons in der Prozessübersicht.
Bearbeiten von Elementen
Jedes Element besitzt eine Bezeichnung und kann mittels der Eigenschaft Dokumentation genauer beschrieben werden. Die Bezeichnung lässt sich entweder über das Eigenschaftsfeld ändern oder über einen Doppelklick auf dem Element im Prozessschaubild. Die Bezeichnung erlaubt einfache HTML-Formatierungen wie <b>,<i>,<br>. Besondere Zeichen wie <,>,& müssen als HTML-Entitäten mit <,>,& beschrieben werden.
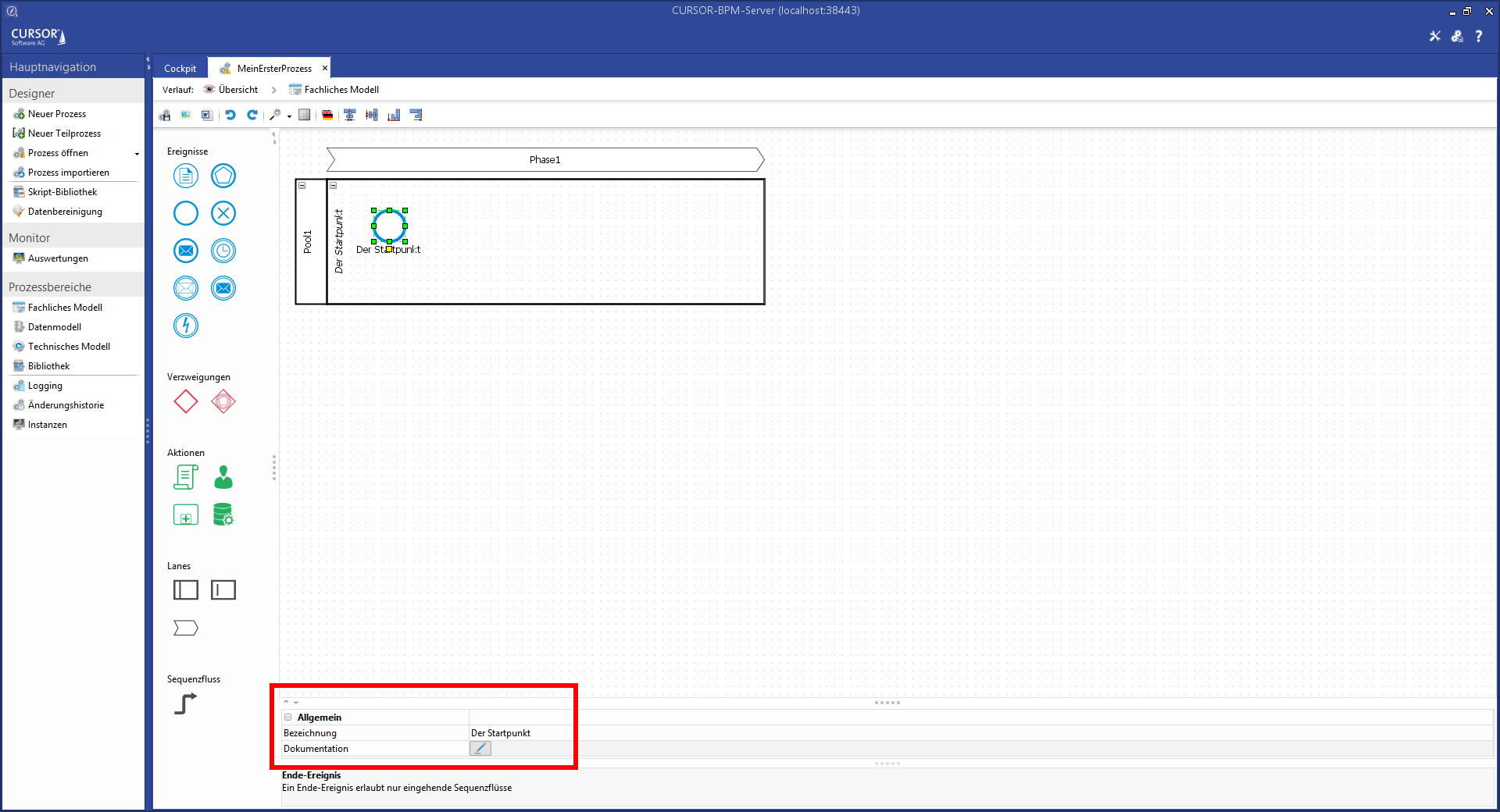
Die Dokumentation wird per Klick auf den Schalter Unbekannter Anhang im Feld Dokumentation in einem HTML-fähigen Editorfenster hinterlegt:
So können Sie mittels Drag and Drop Elemente aus der Palette zeichnen und beschreiben.
Tipp
Verwenden Sie sinnvolle und verständliche Bezeichnungen, um den Prozess im Groben bereits aus der Prozessgrafik verstehen zu können. Verwenden Sie beispielsweise ein Objekt und ein Verb zum Beschreiben der Aktivitäten.
Prozessablauf
Um den Prozessablauf zu visualisieren, verbinden Sie die einzelnen Prozesselemente. Dazu fahren Sie mit gedrückter UMSCHALT Taste mit dem Cursor über das erste Element, hierdurch ändert sich das Aussehen des Elementes. Sobald das zu verbindende zweite Elemente einen grünen Rahmen erhält, sind die Elemente miteinander verbunden.
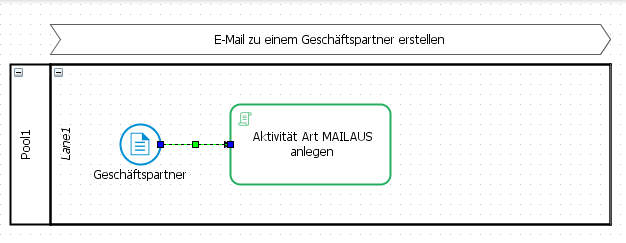
Wenn sie dieses Vorgehen bei Aktivitäten nutzen, können sie so schnell mehrere miteinander verknüpfte Aktivitäten generieren.
Das nachträgliche Ändern des Flusses ist möglich, indem Sie das Fluss-Element markieren und den Start- oder Endpunkt auf ein anderes Element verschieben. Zudem können Sie die Linie des Flusses beeinflussen, indem Sie die grüne Markierung des Fluss-Elementes verschieben:
Änderungen rückgängig machen
Änderungen am Modell, wie das Einfügen von neuen Elementen oder das Verschieben oder Verbinden von Elementen und Kanten, können Sie über die Schalter ![]()
![]()

Zellen-Ausrichtung

Selektierte Elemente im Modell können Sie über die separate Schalterleiste in ihrer Ausrichtung verändern. Für die Tastaturbedienung können Elemente mit den Pfeiltasten verschoben werden.
Internationalisierung
CURSOR-BPM stellt sicher, dass Sie Ihre Prozesse in allen unterstützten Sprachen modellieren und bearbeiten können. So öffnet sich CURSOR-BPM in der eingestellten Systemsprache des Anwenders bzw. in der Sprache, mit der der Anwender das CRM gestartet hat. Auf diese Weise kann jeder Prozessdesigner in seiner gewünschten Sprache arbeiten. Für die sprach übergreifende Modellierung und die Ausführung gibt es zudem die Möglichkeit, dass Sie pro Prozesselement oder pro Prozess die Sprache umstellen können. Sie arbeiten also weiter in der eingestellten Oberfläche, allerdings sehen Prozessausführende den Prozess ggf. in einer anderen Sprache.
Prozesselemente internationalisieren
In den beiden Prozessmodellen befindet sich der Schalter Internationalisieren. Dieser dient dazu, für das aktuell markierte Element die Übersetzung zu hinterlegen. Dazu öffnet sich eine Tabelle, in der die Bezeichnung und die Dokumentation der markierten Elemente angezeigt und geändert werden können.
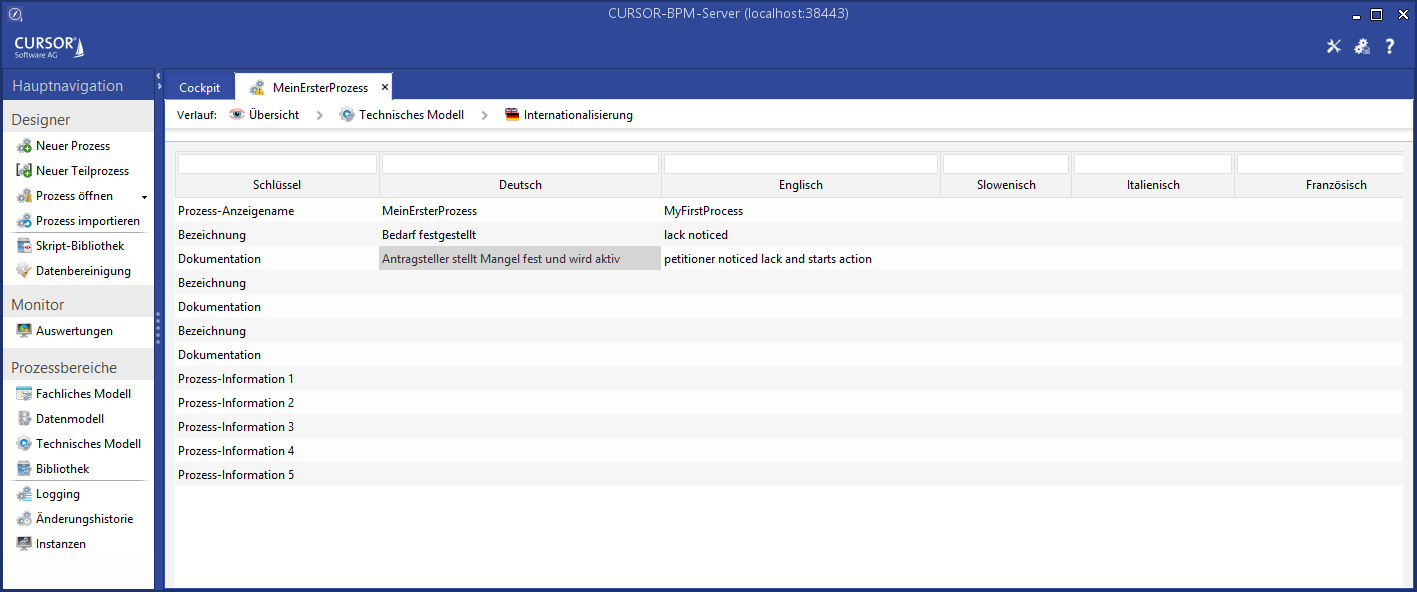
Wurde kein Element explizit markiert, werden alle Elemente des Prozesses angezeigt. Dies kann ebenfalls dazu genutzt werden, um den Namen des Prozesses zu übersetzen.
Modellierung im technischen Modell
Die Modellierung im technischen Modell ist im Wesentlichen identisch zum fachlichen Modell. Es gibt jedoch zusätzliche Elemente in der Palette, die weitere Konfigurationsmöglichkeiten und Editoren bieten. Details hierzu sind in den jeweiligen Kapiteln zu den Elementen zu finden.
Haben Sie sinnvollerweise mit der fachlichen Prozessmodellierung begonnen, so können Sie das fachliche Modell als Grundlage für das technische Modell übernehmen. Dies ist auch nachträglich möglich, wenn schon sie mit der Modellierung des technischen Modells begonnen haben. Eine Übernahme über den Schalter Aus fachlichem Modell erzeugen überschreibt dann den bisherigen Stand. Diese Kopierfunktion nimmt Ihnen die Definition des grundsätzlichen Prozessdesigns ab. Dabei wird der erste, also der oberste Pool aus dem fachlichen Modell in das technische Modell übernommen. Alle Eigenschaften bis auf die Bezeichnung und die Dokumentation der einzelnen Elemente müssen Sie selbstverständlich nachträglich detaillieren und gegebenenfalls weitere Elemente ergänzen. Bitte beachten Sie, dass im technischen Modell nur ein Pool zulässig ist und daher nur der erste, also oberste Pool aus dem fachlichen Modell beim Kopieren übernommen werden kann.
Veröffentlichen
Ein weiterer Unterschied zum fachlichen Modell ist, dass das technische Modell die Grundlage zur Ausführung des Prozesses darstellt. Dazu muss der erstellte Prozess im CRM-System über den Schalter Veröffentlichen (aus dem technischen Modell oder aus dem Prozess-Cockpit heraus) aktiviert werden. Nach der erfolgreichen Veröffentlichung steht der Prozess in der Anwendung zur Verfügung. Er startet, sobald die entsprechende Startbedingung erfüllt ist. Der Status des Prozesses wird Ihnen in der Übersicht des Prozesses auf der rechten Seite angezeigt.

Alle Elemente aus der Bibliothek werden für diese Prozess-Ausführungsversion kopiert. D.h. Änderungen an Suchen und Masken in der Bibliothek haben keinen Einfluss auf schon laufende Prozess-Instanzen. Diese Änderungen werden erst mit der nächsten Veröffentlichung für die neue Prozess-Version wirksam. Im Gegensatz dazu wirken sich Änderungen an der Skript-Bibliothek direkt in den Prozess-Skripten aus.
Die Gültigkeit des Prozess-Modells wird vor dem Veröffentlichen geprüft.
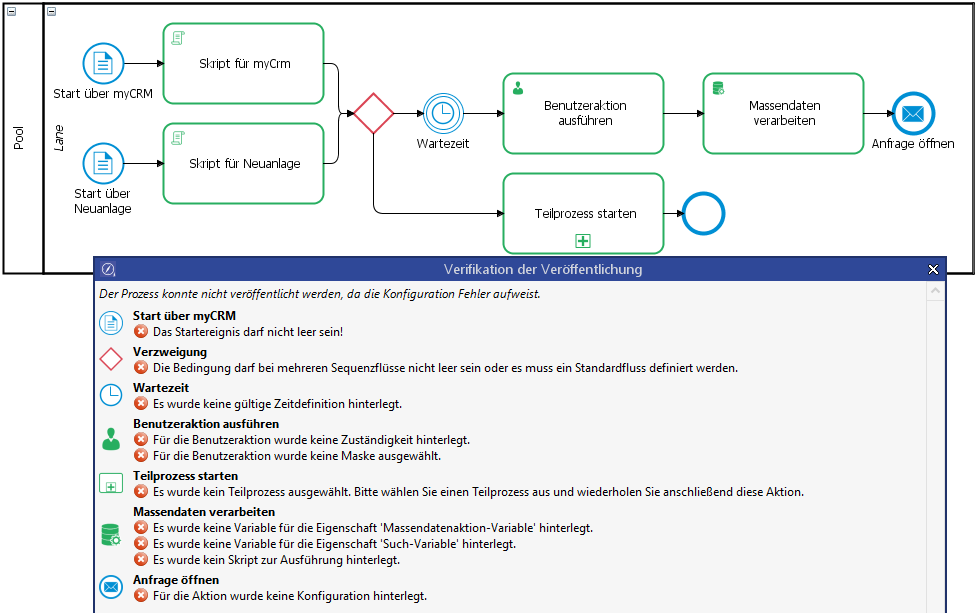
Über den Dialog kann die fehlerhafte Aktion im Prozess-Modell markiert werden. Erst wenn alle Fehler im Prozess-Modell behoben sind, kann der Prozess veröffentlicht werden. Eine Prüfung auf gültige Definitionen von Prozessvariablen erfolgt nicht, da sich dies im Laufzeitverhalten der Prozesse unterscheiden kann.
Per Customizing-Transport importierte Prozesse werden automatisch im Zielsystem veröffentlicht.
Sofern ein Prozess nicht mehr verwendet werden soll, können Sie ihn deaktivieren. Bereits gestartete Prozess-Instanzen können zu Ende geführt werden. Der Prozess lässt sich jedoch nicht nochmals starten.
Löschen
Sie können nicht mehr benötigte Prozesse mittels Klick auf das Trash-Symbol löschen. Hierdurch wird der Prozess aus dem System entfernt, sofern der Prozess zuvor deaktiviert wurde und es keine laufenden Instanzen des Prozesses mehr gibt. Wir empfehlen Ihnen, vor dem Löschen eines Prozesses diesen zu Sicherungszwecken zu Exportieren. Bei Bedarf können Sie ihn dann einfach importieren oder zumindest eine vollständige Prozessdokumentation zu speichern. So können Sie das im Prozess enthaltene "Wissen" immer wieder einsehen.
Grundlegende Hinweise zu Scripting in Benutzer- und Skript-Aktionen
Für korrektes Scripting sowohl in Benutzer- als auch in Skript-Aktionen sollten Sie mit Konzepten zu Datentypen, Gültigkeitsbereichen von Variablen und Zuordnungsoptionen von Unterbereichsinformationen vertraut sein.
Achtung
Grundsätzlich besteht eine Support-Unterstützung für Skripte nur bei Verwendung der von CURSOR bereitgestellten Hilfsklassen und der Java-Standard Datentypen sowie Methoden. Für die Verwendung von Dritt-Bibliotheken besteht kein Unterstützungsanspruch an CURSOR. Wurden in der Skript-Umsetzung interne Objekte und Klassen der CRM-Umgebung referenziert, die nicht über die Skript-Dokumentation freigegeben sind, so kann für keine release-sichere Übernahme bei einem Update auf eine neuere Version garantiert werden.
Zusammenhang von Workspaces, Entries, Containern und Values
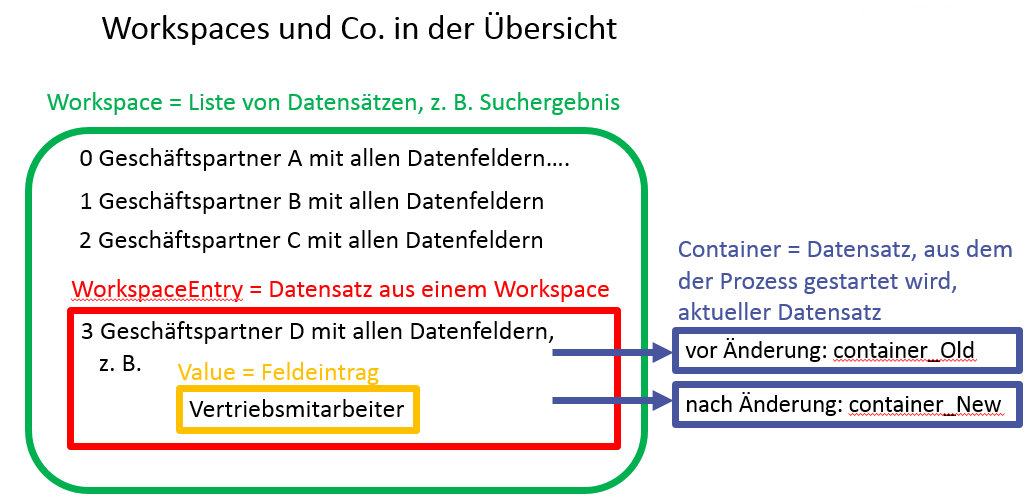
Unterschiede von Prozess- und Aktions-Variablen

Definition von Entitäten-Zuordnungen in Unterbereichen
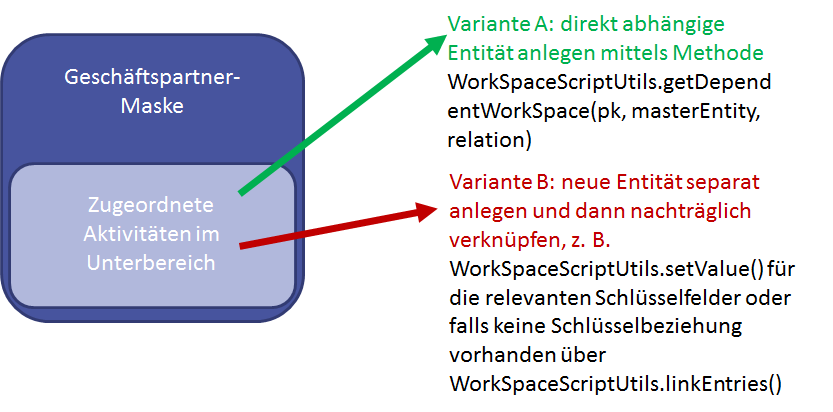
Synchronisieren von Daten im CRM und Prozessen
Die Prozess-Variablen können Datensätze aus dem CRM enthalten. Diese Datensätze wurden aus dem CRM geladen, können aber mit der Zeit veralten, wenn diese Daten nicht immer wieder aktuell aus dem CRM-System gelesen werden. Dieses Problem kann schon auftreten, wenn ein Datensatz per BPM-Skript-Aktion gelesen und der Benutzer-Aktion übergeben wird. Bearbeitet der Anwender die Benutzer-Aktion erst nach einigen Tagen, so ist der Datensatz in den Prozess-Variablen veraltet, d.h. aktuelle Änderungen am Datensatz sind nicht im Benutzertask sichtbar. Dieses Problem betrifft auch eingehende Zwischen-Ereignisse, die in der Nachverarbeitung auf veraltete Daten zurückgreifen könnten.
Diese Datensätze werden als Variablen mit dem Datentyp IContainer verwaltet. In der Variablen-Definition können diese Variablen mit der Option automatisch synchronisieren markiert werden. Jede Benutzer-Aktion erlaubt es, Datensatz-Variablen beim Öffnen der Aktion automatisiert zu aktualisieren, so dass immer die korrekten Daten dem Anwender angezeigt werden. Um Änderungen durch den Benutzer auch direkt in das CRM-System durchzuschreiben, kann die Option automatisch schreiben aktiviert werden. Das automatische Lesen und Schreiben wird auf alle verfügbaren IContainer-Variablen der Prozess-Instanz angewandt. Gespeichert werden nur die Datensätze, deren Daten im Prozess geändert wurden. Der Mechanismus zum Daten aktualisieren ist auch in den Zwischen-Ereignissen verfügbar.
Behandlung von Update-Konflikten
Update-Konflikte und verfügbare Lösungsmöglichkeiten
Daten, die bei einer Prozessausführung verändert wurden, können in das CRM mittels Skript-Methoden zurückgeschrieben werden. Beim Arbeiten im CRM kann es dabei zu Update-Konflikten kommen, z. B.:
-
wenn relevante Daten im CRM in folgendem Zeitraum geändert wurden: nach dem Laden der ursprünglichen Daten für einen Prozess und vor dem Speichern der Prozessdaten zurück ins CRM oder
-
wenn der Datensatz von zwei Personen gleichzeitig bearbeitet wird.
Update-Konflikte können insbesondere dann auftreten, wenn zwischen dem Laden von Daten und dem Speichern von Daten mehrere Stunden/Tage liegen, z. B. wenn sie in verschiedenen Skript-Aktionen stattfinden, die durch eine Benutzeraktion unterbrochen wurden. In diesem Fall kann es passieren, dass der in der Prozessausführung geladene IContainer veraltete Daten enthält: d.h. beim Speichern werden Änderungen eines anderen Anwenders bzw. einer anderen Aktion ohne Rückfrage überschrieben.
Schematische Darstellungen zum Zusammenhang der Datenhaltung in Prozessen und im CRM finden Sie im separaten Handbuchkapitel Technische Rahmenbedingungen / DatenhaltungzwischenBPM-ProzessundCRM.
Ab der Version 15.1 wird das Update-Datum im Datensatz gegen den aktuellen Wert in der Datenbank verglichen. Ist der Datenbank-Wert neuer, so kommt es zu einer UpdateConflictException. Dieser Fehler kann über den Update-Konflikt-Dialog in einer Benutzer-Aktion vom Benutzer selbst aufgelöst werden, indem er die zu schreibenden Daten bestimmt wie folgt definiert:
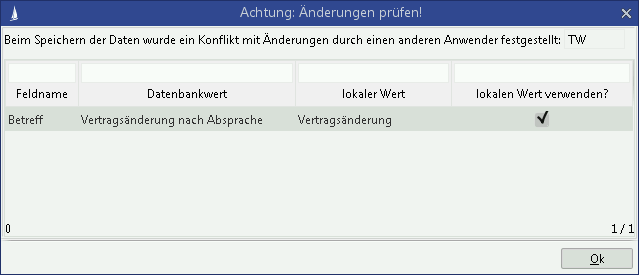
Mit der Bestätigung ("Ok") wird das gesamte Speichern-Skript nochmals ausgeführt, jedoch diesmal mit dem entsprechend aktualisierten Datensatz.
Voraussetzungen im Skripting zur korrekten Behandlung von Update-Konflikten
Korrektes, vollständiges Laden der relevanten Datensätze
Der Mechanismus zur Erkennung von Update-Konflikten setzt voraus, dass in den Prozess-Skripten der Datensatz vor dem Schreiben auch korrekt (im Sinne von vollständig) aus dem IScriptWorkSpace geladen wurde. Denn die Änderungen am Datensatz werden nur dann gespeichert, wenn die geänderten Felder schon im geladenen Datensatz vorhanden sind. Das CRM muss zum Speichern von Daten den Datensatz ebenfalls immer vollständig laden (vgl. Listenansicht und Detailansicht).
Das folgende Beispiel zeigt eine Programmierung, in dem ein Datensatz nicht vollständig geladen wurde, so dass er später nicht korrekt gespeichert werden kann:
falsche Programmierung
IContainer entry = WorkSpaceScriptUtils.searchEntryForRead("abc", "Activity")
WorkSpaceScriptUtils.setValue(entry, "Subject.Activity", "abc")
...
IScriptWorkSpace workSpace = WorkSpaceScriptUtils.searchEntry("abc", "Activity") //der Datensatz wurde nicht vollständig geladen!
WorkSpaceScriptUtils.saveEntry(workSpace, entry) //das Speichern wird nicht korrekt funktionieren
Das korrekte Skript lautet folgendermaßen:
korrekte Programmierung
IScriptWorkSpace workSpace = WorkSpaceScriptUtils.searchEntry("abc", "Activity")
IContainer entry = WorkSpaceScriptUtils.getEntry(workSpace, 0) //der Datensatz wurde vollständig geladen!
WorkSpaceScriptUtils.setValue(entry, "Subject.Activity", "abc")
...
WorkSpaceScriptUtils.saveEntry(workSpace, entry) //das Speichern wird nun korrekt funktionieren
Nur in diesem Fall werden die Änderungen am IContainer nun korrekt in die Datenbank übertragen.
Aufrufe von 'WorkSpaceScriptUtils.saveEntry' nur mit Zuweisung des Rückgabe-Containers zwecks Aktualisierung der im Prozess vorgehaltenen Referenzdaten
Die neue Erkennung der Update-Konflikte führt in bestehenden Prozessen zu Problemen, wenn dort nicht mit aktuellen Prozess-Referenzdaten gearbeitet wird, die zur Erkennung von Update-Konflikten beim Speichern in die CRM-Datenbank herangezogen werden:
Der folgende Prozessgraph zeigt ein Modell für einen Ablauf mit potentiellen Update-Konflikten, die im Folgenden weiter erläutert werden:

Der folgende Skript-Auszug zeigt, dass in der "Vorbereitung" der Datensatz geladen wird:
Vorbereitung
IContainer entry = WorkSpaceScriptUtils.searchEntryForRead("abc", "Activity")
ProcessUtils.setVariable("entry", entry)
Als nächstes wird der Datensatz in einer Benutzeraktion verändert:
Datenmaske
completetask()
{
WorkSpaceScriptUtils.setValue(entry, "Subject.Activity", "abc")
...
}
Die Änderungen aus der Benutzer-Aktion werden anschließend gespeichert:
Änderungen speichern
IScriptWorkSpace workSpace = WorkSpaceScriptUtils.searchEntry("abc", "Activity")
WorkSpaceScriptUtils.getEntry(workSpace, 0)
WorkSpaceScriptUtils.saveEntry(workSpace, entry)
Im ersten Durchlauf (also beim ersten Speichern von Daten durch den Prozess in die CRM-Datenbank) muss es zu keinem Update-Konflikt kommen. Ein Konflikt könnte jedoch entstehen, falls der Datensatz durch eine andere Person in der Zwischenzeit bearbeitet wurde. Dieser kann wie oben beschrieben mit dem Update-Konflikt-Dialog aufgelöst werden.
Sind aber im Prozess Nacharbeiten nötig, so wird es im zweiten Prozessdurchlauf immer zu einem Update-Konflikt kommen aufgrund der aufgeführten Skriptings.
Dieses Problem resultiert daraus, dass durch die erste Speicherung im Prozess der Datensatz in der Datenbank aktualisiert wurde. Allerdings wurde diese CRM-Datenänderung nicht zurück in den Prozess geschrieben. Die Prozessausführung kennt somit als ursprüngliche Daten noch den Stand vom erstmaligen Datenladen. Bei einem zweiten Speichern von Daten aus dem Prozess heraus ins CRM würde also ein Update-Konflikt erkannt werden, da die Datenstände vom Prozess zum Startzeitpunkt und die aktuellen CRM-Daten (die ja zwischenzeitlich vom Prozess verändert wurden) verglichen werden.
Daher ist es wichtig, dass auch die Daten, die dem Prozess bekannt sind (Referenzdaten für die Erkennung von Update-Konflikten), aktualisiert werden. Dies wird erreicht, indem der Rückgabewert aus der Methode WorkSpaceScriptUtils.saveEntry wieder der IContainer-Variable zugewiesen wird, so dass die Prozess-Variable für die weitere Verwendung aktualisiert ist.
Für das Beispiel wäre also folgendes Skripting vorzunehmen:
Änderungen speichern - korrekt!
IScriptWorkSpace workSpace = WorkSpaceScriptUtils.searchEntry("abc", "Activity")
WorkSpaceScriptUtils.getEntry(workSpace, 0)
IContainer newEntry = WorkSpaceScriptUtils.saveEntry(workSpace, entry)
ProcessUtils.setVariable("entry", newEntry)
Damit ist sichergestellt, dass die Prozessausführung die eigenen Datenänderungen nicht als Update-Konflikt erkennt.
Um diese Probleme im Vorfeld des Updates nach 15.1 zu erkennen, können Prozesse mit einer Aktion ![]()
Die Prüfung (ab 14.1.09) sucht nach Aufrufen von WorkSpaceScriptUtils.saveEntry ohne eine Zuweisung des Rückgabe-Containers.
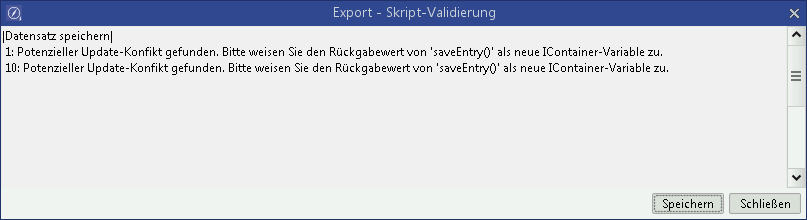
Diese Prüfung findet auch während des Updates auf 15.1 statt, so dass potenziell gefährdete Prozesse vom Update-Tool angezeigt und zusätzlich im Log der Update-Routine zu finden sind.
Neben den genannten Mechanismen im Vorfeld vom und beim Update auf 15.1 wird die Skriptvalidierung auch stets beim Speichern einer Skript-Aktion ausgeführt.
Zusammenhänge zwischen Datensynchronisation zwischen Prozess und CRM sowie Behandlung von Update-Konflikte
Um die Update-Konflikte weiter zu minimieren, sollten Datensatz-Variablen im Prozess möglichst häufig aktualisiert werden. Aktualisiert eine Benutzer-Aktion für die Bearbeitung die Datensatz-Variablen beim Öffnen, so arbeitet der Prozess automatisch mit den neusten Daten aus dem CRM. Voraussetzung ist, dass diese Variable vom Typ IContainer mit der Option automatisch aktualisieren gekennzeichnet und in der Benutzer-Aktion die Option automatisch Lesen gesetzt ist. Beim Öffnen der Benutzer-Aktion werden alle in der Prozess-Bibliothek definierten und zur Laufzeit gültig gefüllten Datensatz-Variablen aktualisiert. Nicht nur diejenigen, die gerade in der Benutzeraktion benötigt werden. Es gilt zu beachten, dass Datensatz-Variablen - durch eine Suche oder durch manuelles Setzen - Daten aus anderen Entitäten enthalten können. Diese Daten werden durch das automatische Aktualisieren verworfen.
Das Automatische Schreiben am Ende einer Benutzer-Aktion wird auf alle verfügbaren Datensatz-Variablen angewendet, nicht nur auf den Datensatz, der gerade durch den Anwender bearbeitet wurde. Enthalten Datensätze keine Änderung, so findet auch keine Aktualisierung statt. Auch hierbei kann es zu einem Update-Konflikt kommen, wenn der zu schreibende Datensatz durch einen anderen Anwender zeitgleich bearbeitet wurde oder die Option automatisch Lesen deaktiviert ist. Über den Dialog zur Behandlung von Update-Konflikten können diese aufgelöst werden. Der Dialog erscheint mehrmals, falls mehrere Datensatz-Variablen betroffen sind.
Handhabung von lang andauernden Transaktionen
Je nach Prozessbedarf kann es sinnvoll sein, Prozesse mit einer zeitlichen Verzögerung zu starten, z. B. damit Datenbankaktionen des vorherigen Prozesses ausreichend Zeit haben, abgeschlossen zu werden, damit der neue Prozess auf diese geänderten Daten in der Datenbank zugreifen kann. Diese Option der zeitlichen Verzögerung wurde jetzt in die Methode ProcessUtils.startProcess eingefügt, so dass jetzt folgende Parameter zur Verfügung stehen:
-
processId- Díe ID des Prozesses -
variables- Mapping mit Variablen -
isAsychonous- TRUE der Prozess wird asynchron gestartet. -
delay- Zeitversatz in Millisekunden für das asynchrone Starten. Der Standard sind 1000ms für einen sicheren Transaktionsabschluss. Der Parameter ist optional.
Beispiel:
ProcessUtils.startProcess("myID", map, false);
Masken und Suchen mit Prozess verknüpfen
Beschreibung
Masken und Suchen können in mehreren Prozessen verwendet werden. Um zu bestimmen, ob eine Änderung auch Auswirkungen auf andere Prozesse hat, muss eine Verknüpfung zwischen dem ProcessContainer und der Maske/Suche in der Datenbank hergestellt werden. Zudem sollten Prozess-Suchen als solche gekennzeichnet werden, wie es bei Masken schon erfolgt.
Suchen als Prozess-Suchen markieren
Die ExtendedSearch Tabelle wird um das Feld SearchType erweitert. Dieses kann mit einem Enum-Wert (Schlüssel) belegt werden. PROCESS steht hier für BPM-Suchen. Die normale Anwendung kann eine BPM-Suche nicht zum Bearbeiten öffnen, dies ist nur über CURSOR-BPM möglich. Alle Suchen in CURSOR-BPM werden automatisch als BPM-Suche angelegt. Nur Prozess-Suchen können einem Prozess im Repository hinzugefügt werden. Diese werden automatisch zu Systemsuchen (Abfrage beim Speichern entfernen).
Verknüpfen von Externen Daten
Bei der Neuanlage oder dem Hinzufügen von Masken/Suchen wird der eine Verknüpfungs-Eintrag in die Tabelle CustRepository (oder eine Tabelle des Customizing-Transports) geschrieben. Dieser Eintrag ist beim Löschen des Prozesses zu entfernen. Beim Ändern von Masken/Suche wird auf die Verwendung in anderen Prozessen geprüft. Wird eine weitere Verwendung erkannt, kann die Änderung auf alle Prozesse angewendet oder abgebrochen werden (Rückfrage beim Anwender).
Durch die Änderung angepasste Prozesse werden mit dem Status 'extern geändert' versehen und erhalten im Änderungslog den Eintrag auf die geänderte Suche.
Prozess-Masken und -Suchen historisieren
In allen Skript-Methoden und Funktionen in BPM-Masken werden nun Masken und Suchen prozessversionsgenau geladen.