Basics
The Juhuuu! search is a full-text search that searches for one or more keywords simultaneously across the entire database. The only prerequisite is that the data has been indexed beforehand. The full text search is used if the entity or essential information about the searched dataset is unknown. Functionality and handling are comparable to Internet search engines such as Google.
This search is particularly useful when rare search terms can be entered. In these cases, it provides manageable quantities of responses. Furthermore, the full text search is often used if the entity or essential information about the searched dataset is unknown.
For the user, the Juhuuu! search is presented in the application window at the top left and can be activated via the button 🔎 or by entering a keyword in the field above.

When you start the search, the full text search window opens and displays a list of search results. If no search term is entered, the full text search window opens and you can enter search terms there. All keywords entered are always linked with a logical AND. The result of your search is displayed in a separate program window. After accessing a search result, you can switch back to the full text search by changing tasks (Alt + ↔ Tab keystroke) and access another dataset. The Advanced Search tab provides additional options for performing the search. Here,for example, you can restrict the search to certain entities.
Administration
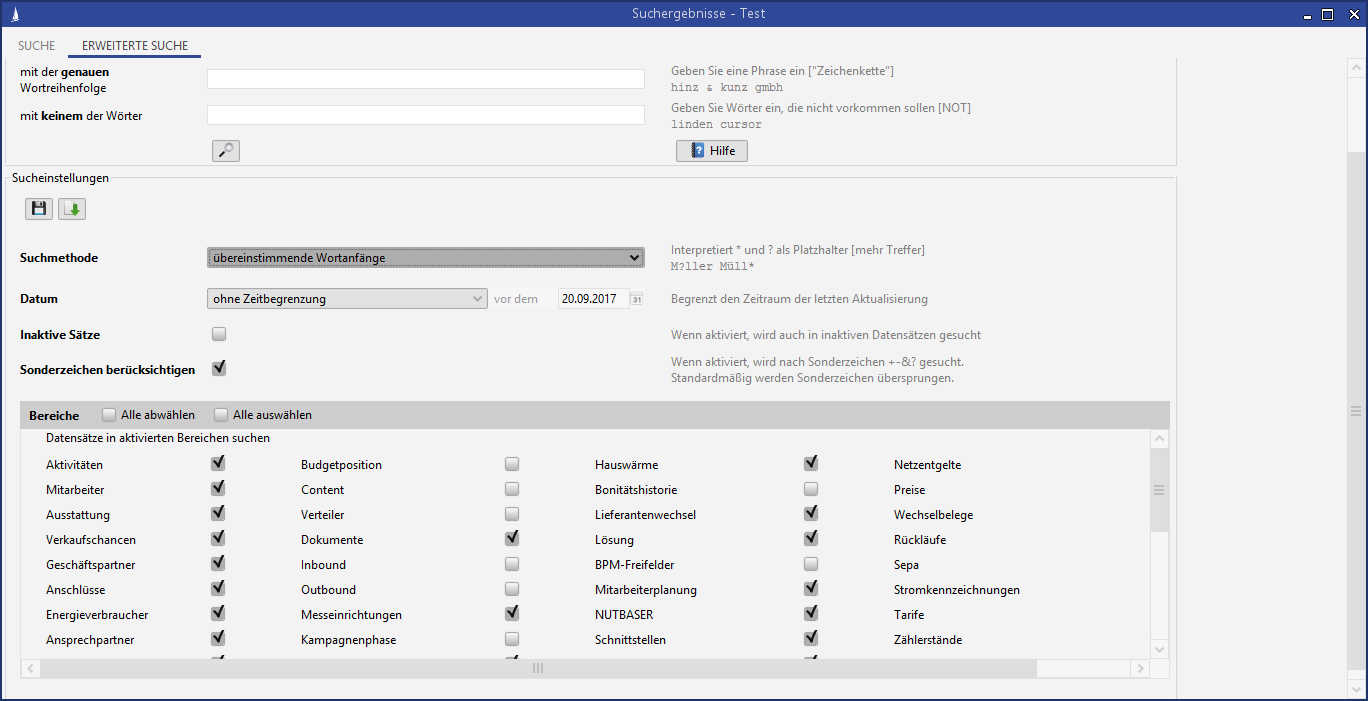
This node sets the behavior of the Juhuuu!-search system-wide. Every administrator is offered this as a default setting and can then make changes.
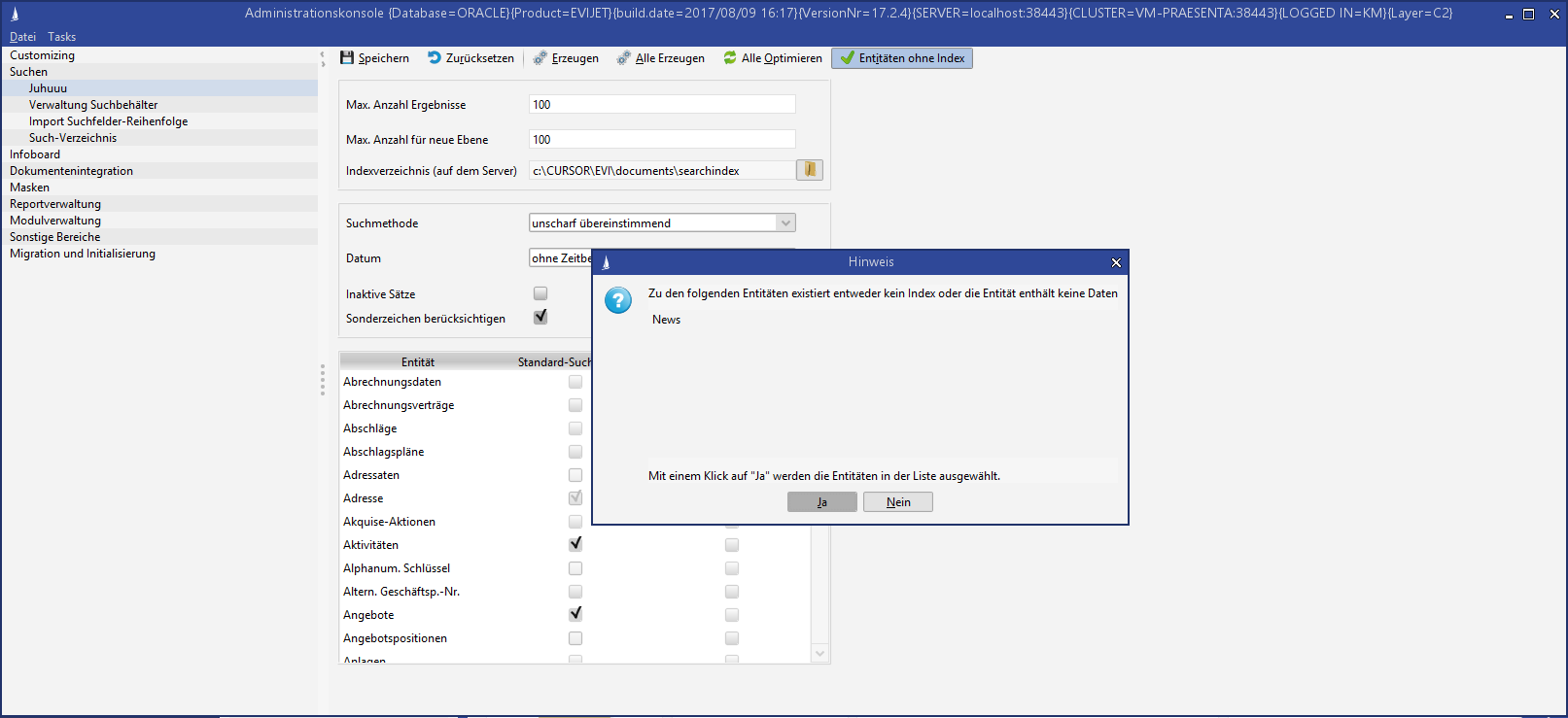
Figure: Configuration of the Juhuuu!- Search
The prerequisite for including an entity in the Juhuuu! index is its release in the Edit entity configuration node. To do this, the entity must be activated in the Searchable Field column. The selection must be confirmed separately for each entity to avoid misconfigurations.
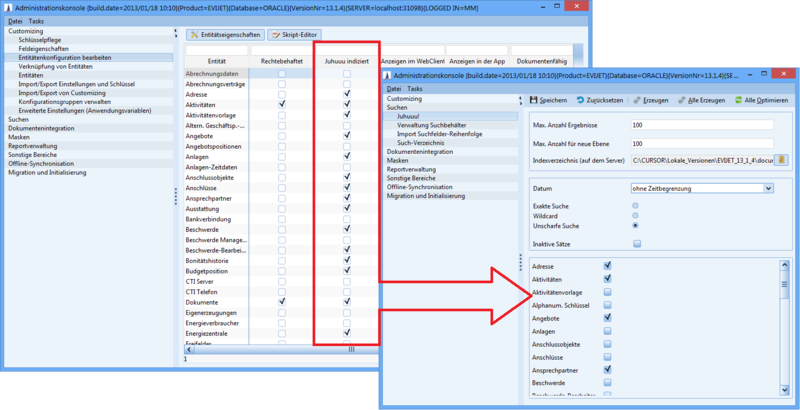
Figure: Edit entity configuration, column: Use for Juhuuu index
After the client has been restarted, the entities enabled in the Juhuuu! node are displayed in the list.
Dialog box
|
Max. number of results |
Sets the maximum number of results displayed. |
|
Max. number for new level |
In addition, multiple search result entries of one entity can be loaded into a new level. The default value is 100. The number of search results for a new level must not exceed the max. number of search results of the Juhuuu! search. |
|
Index directory |
Here you set the server directory (on the application server) in which the special index for the Juhuuu! search is stored. This is NOT a network share for the connected clients. |
|
Date |
This selection list contains options that can restrict the amount of data according to the entry time. (e.g. without time limit, in the last month etc.) |
|
exact search results
|
If this parameter is activated, only exactly matching results are displayed during the search. Case sensitivity is ignored. |
|
Automatic completion of search terms
|
Activates or deactivates the option to use search wildcards in the quick search. The 'Allow search for wildcard characters' field is activated when the mask is opened. This setting is not saved. This setting affects the entries in the 'Advanced search' tab. If the search is started from this page, the wildcard characters are 'escaped' so that you can search for them. If this checkbox is unchecked, wildcard characters are included in the search. When changing to the 'Search' tab, these characters are also 'escaped'. Entries on the "Search" tab are always written in the "Find results with all words" field. This means that changes on this tab are not shared to the "Advanced search" tab. If no changes were made when changing between these tabs, any assignment is retained. |
|
similar search results
|
If this parameter is activated, similarly spelled results are displayed during the search. For example, searching for the name Meyer also finds Mayer. The larger the deviation of the word, the further down it is positioned in the result list. This is not a 'phonetic' distinction. If searching for the word 'Meyer', the results 'Mayer' and 'Leyer' are regarded as equivalent |
|
intelligent
|
combines the fuzzy search and search with autocomplete |
|
Inactive sets |
Using this field, datasets marked as INACTIVE can be included in the search result. |
|
Entity list |
The entity list in this dialog box is used for two actions:
Here you set which entities are taken into account by default. This default setting only affects users who have not saved any individual settings. 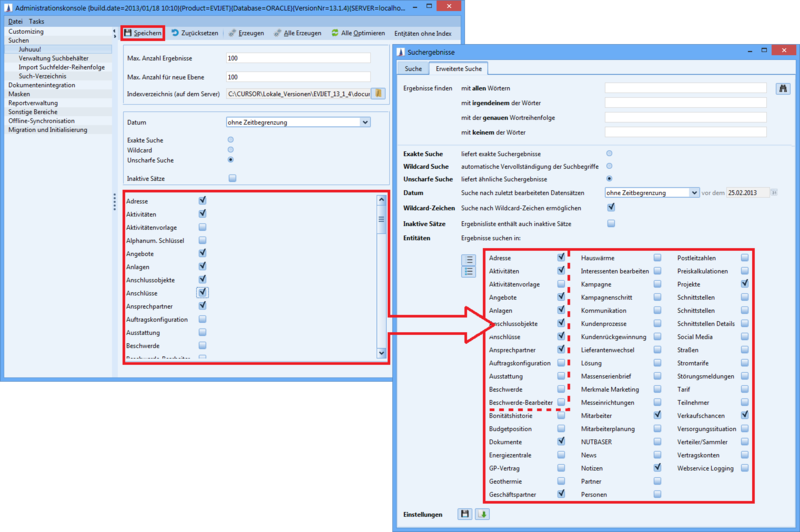
Here you can set for which entities the index is to be newly created. For example, if you have enabled a C2 entity for indexing (Edit entity configuration node), you can only add this entity to the search index. To do this, in the dialog box activate only the entity to be re-indexed and click the Create button. These changes at this point have an immediate impact on the search results. The more objects are included in the index, the more space the index file requires. The fewer objects are indexed, the less successful the quick search becomes, since many areas are then no longer searched. |
|
|
selects all entities |
|
|
deselects all entities |
|
|
Click on the button to save the current visible settings in the mask. |
|
|
resets the setting to the last saved setting |
Toolbar
|
|
The set parameters can be saved to a file. |
|
|
The changes currently made on the mask can be undone. |
|
|
The preset parameters can be loaded from a file (e.g. from another CURSOR-CRM/EVI version). |
|
|
When all options are set, clicking the button creates the index file for the full text search. |
|
|
Creates an index file for all entities. Before doing this, you should use the Optimize All button to optimize the search in order not to impair the performance of the system when you run the Juhuuu! search later on. |
|
|
The search is optimized Hint To index the entire dataset for the first time after a migration, for example, follow the instructions below:
The indexing process starts and takes several hours, depending on the amount of data. It is recommended that you start the process in the evening or at the weekend so that productive operation is not impaired by the process. |
|
Entities without index |
It is possible that no index exists for an entity even though the entity has been activated for indexing. Whether due to an error during index generation or the entity does not contain any data (for example, an empty, newly created C2 entity). Click this button to identify the entity. In the following dialog, you can copy the entities for re-indexing. This is how you proceed:
|
Logic of entity indexing
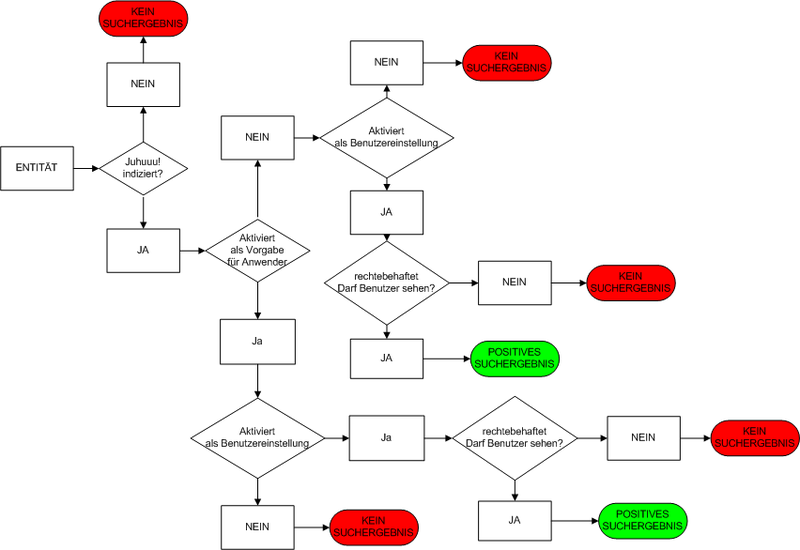
Result
For search results to be positive, the following requirements must be met:
-
the entity must be activated for indexing
-
the entity must be activated in the configuration settings
-
the user must have appropriate rights (right to see the entity and the dataset)
The index is created for all explicitly activated entities. Only in the last step does the system check whether the user performing the search has the right to see the entity and the dataset.
Effect of logic in the Web Client
The same index is also used in the Web Client. If several entities are indexed via the Windows client, the data is available for retrieval. Using the Web Client, exactly the same conditions must be met for datasets to be found:
-
the entity must be activated for indexing
-
the entity must be activated in the configuration settings
-
the user must have appropriate rights (right to see the entity and the dataset)
To activate the entity in the configuration settings, the entity must be enabled for the Web Client in the Edit entity configuration node. If not, the entity is not displayed in the configuration settings and cannot be included in the search.
Configuration of the suggestion lists
The lookup suggestion list is generated by the Lucene search. Lucene cannot search for "contains". The order of the search results is deliberately not affected, since the order after the Lucene weighting (the so-called score) is used. If the results were sorted, this would result in a very inefficient response time for large amounts of data, since the search result would first have to be built up and completely sorted.
The lookup suggestion list searches on the LookupContent field of the LuceneIndex, whose content can be set via the configuration Juhuuu lookup index fields in the entity properties.
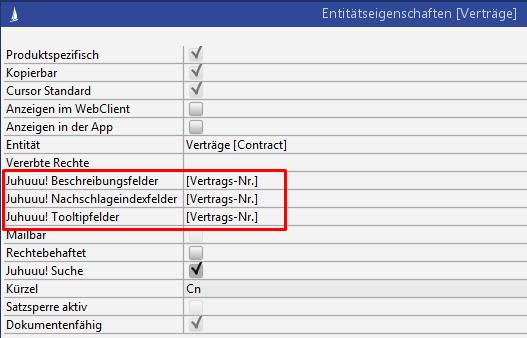
Figure: Configuration of the lookup index fields
Example: the Contract Status field is included in the delivery status. With this configuration only the numbers are found:
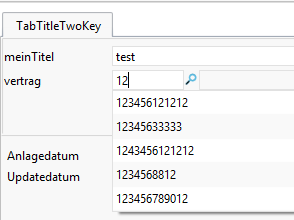
The numbers were included in the system:
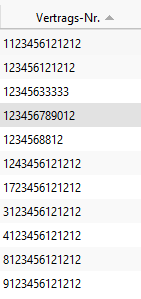
However, if the contract number contains a "whitespace" such as an underscore, these results are also found.
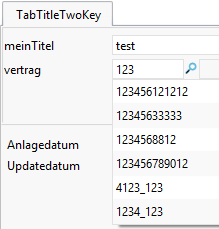
For contract numbers:
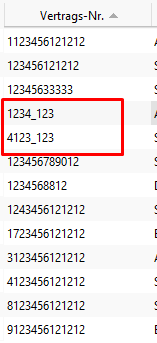
Transfer results set to list
In the Juhuuu! search mask, the user can open a search result entry in a new level. This is done by clicking on the search result entry. In addition, multiple search result entries of one entity can also be loaded into a new level.
Loading data using the context menu in the search result entry
Right-clicking on a search result entry opens a context menu with the option of loading several entries of this entity from the search results set directly into a new level. The restriction of the quantity (here 100) can be configured in the Administration Console.
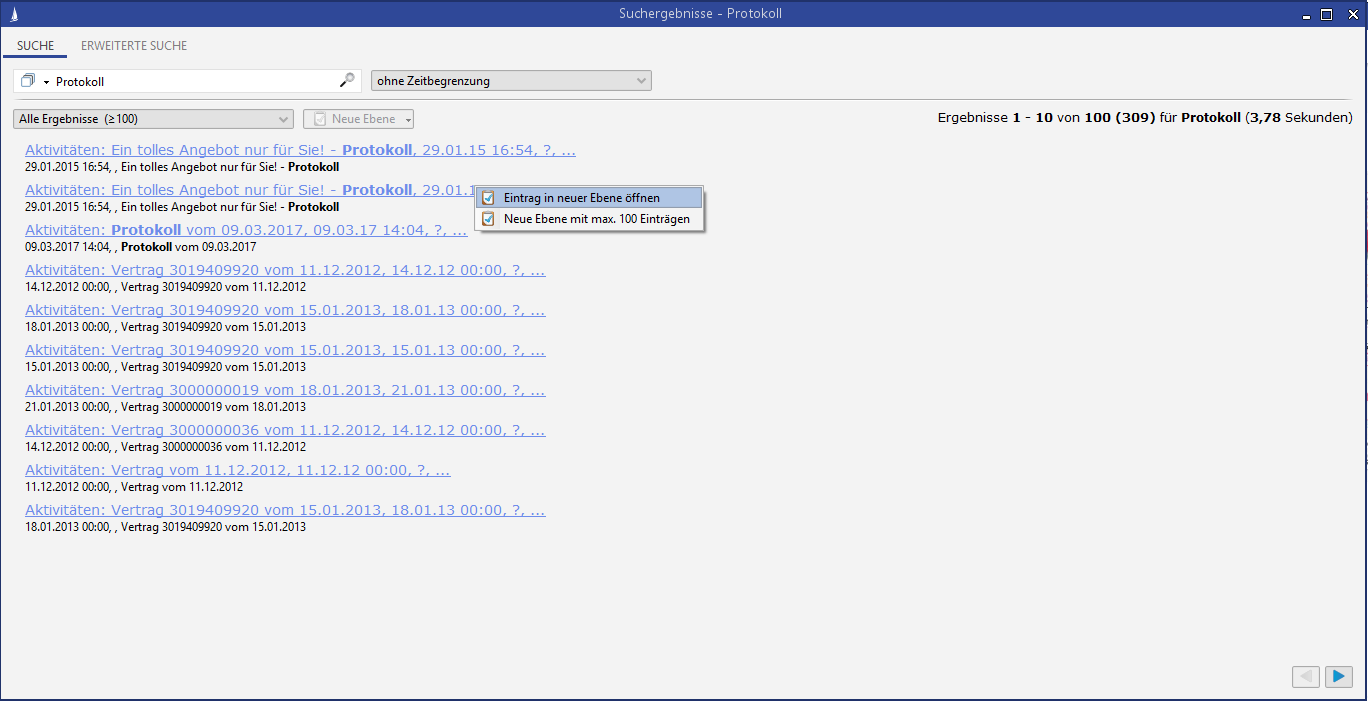
Figure: Example of context menu for search results entry
Loading data via new level button
The New level button is located next to the selection field for entities. This allows you to load the search results set of an entity into a new level. Clicking on the button loads a recommended number of search result entries into the new level. This value can be configured in the administration of the Juhuuu! search.
In case you want to load even more search result entries in the new level, use the context menu.
-
The default action of the button always corresponds to the first entry in the context menu
-
The button becomes active as soon as an entity has been selected in the selection box.
-
The maximum search result size for a new level is equal to the maximum size of the results of the Juhuuuu! search. The maximum size of the search results of the Juhuuu! search is configured in the Administration Console.
Indexing
Data formats
In addition to the entities that can be configured in the Administration Console, the full text search also indexes the documents stored in the application with the document type INTERNAL. This includes documents created from CURSOR-CRM (e.g. single letters) as well as imported documents (e.g. by drag & drop). Only documents that are stored as links (for example in an archive) are excluded. Indexing is carried out for files with the following file types: xls, xlsx, ppt, pptx, doc, docx, dot, dotx,xlsm, dotm, docm, pptm, pdf, txt, htm, html and rtf, whereby only text-based documents are indexed (e.g. no scanned PDF files).
Tip
Check your PDF driver to see if a text-based PDF document is generated.
Encrypted PDF documents
Indexing of encrypted internal PDF documents can be managed using the following PropertyMapper entries:
Set the global password that is also used to encrypt PDF documents (this password must be used in the PDF creation tool):
id 'SYSTEM_NODE:/de/cursor/jevi/server/system/search/simplesearch/documents/handler/PDFBoxPDFHandler$!!$GeneralPdfPassword'
propertyType 'SYSTEM'
propertyValue 'meinPasswort'
If this functionality is not used, it can be disabled using the following entry:
id 'SYSTEM_NODE:/de/cursor/jevi/server/system/search/simplesearch/documents/handler/PDFBoxPDFHandler$!!$TryPdfDecryption'
propertyType 'SYSTEM'
propertyValue 'false'
Benefits:
PDF files that have to be sent to customers encrypted can now be indexed with the Lucene search.
Maintenance
If the indexing has been carried out once, the Juhuuu! search is ready for use. All changes to data or all new entries are automatically included in the index. In order to ensure optimal search results, it is recommended to optimize the index once a month. This process only takes a few minutes. It combines several indexes and removes deleted data from the index. Due to technical circumstances, such as parallel editing of data by several users, very rarely it is possible that changes cannot be included in the index. In order to minimize the amount as much as possible, you can start complete indexing from time to time.
If you wish to automate indexing and optimization of the indices to reduce the administrative effort, please contact CURSOR Software AG.
Stop words
Stop words
Stop words are simple expletives without advantage for big data, which is why they are excluded to keep the index low.
-
By default, no stop word list is used
-
You can use the PropertyMapper to configure which stop words can be used
-
with (17.1)
ID='/de/cursor/jevi/common/lucene/AnalyzerFactory$!!$StopWords'
or (16.1)
ID= 'SYSTEM_NODE:/de/cursor/jevi/common/lucene/AnalyzerFactory$!!$StopWords'
stop words can be stored using the
$!!$separator (CN layer) -
If the value
getDefaultStopSet()is stored in this PropertyMapper entry, the previous default is used.
-
The server must be restarted and the indices re-indexed after making any changes.
-
Stop words for the German language
Stop words list (currently only German stop words are considered):
"als", "am", "auf", "aus", "das", "dass", "daß", "der", "dich", "die", "dir", "du", "durch", "eine", "einem", "einen", "einer", "eines", "er", "es", "für", "ihr", "ihre", "ihres", "im", "in", "ist", "kein", "mein", "mich", "mir", "mit", "oder", "ohne", "sein", "sie", "und", "von", "war", "was", "wegen", "wer", "wie", "wir", "wird"
Area ranking for COMMAND search results
The ranking of the different areas can be changed via a configuration setting, so that individual areas can be weighted higher and thus the results from this area are displayed higher up.
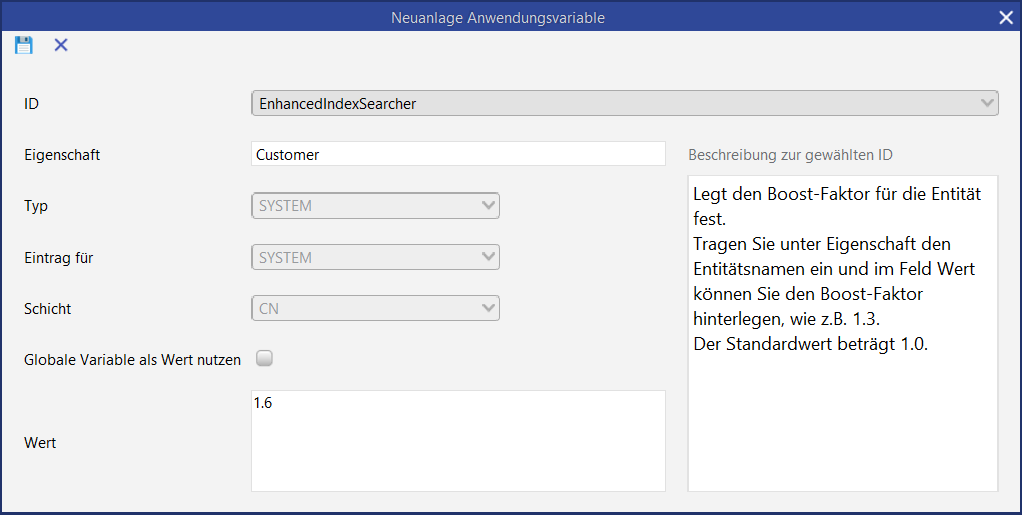
Figure: Weighting configuration
In the EnhancedIndexSearcher application parameter, the weighting for areas can be configured.
In principle, the weighting is carried out according to the following logic:
-
If there is no entry for an area the score is 1.0
-
Everything below 1.0 devalues the area
-
Everything above 1.0 upgrades the area
The following scoring settings are delivered:
-
Business partner: 1.5
-
Contact person: 1.3
-
Employee: 1.2
-
Activity: 0.25
-
Documents: 0.1
-
Projects: 0.25
-
Incident: 0.25
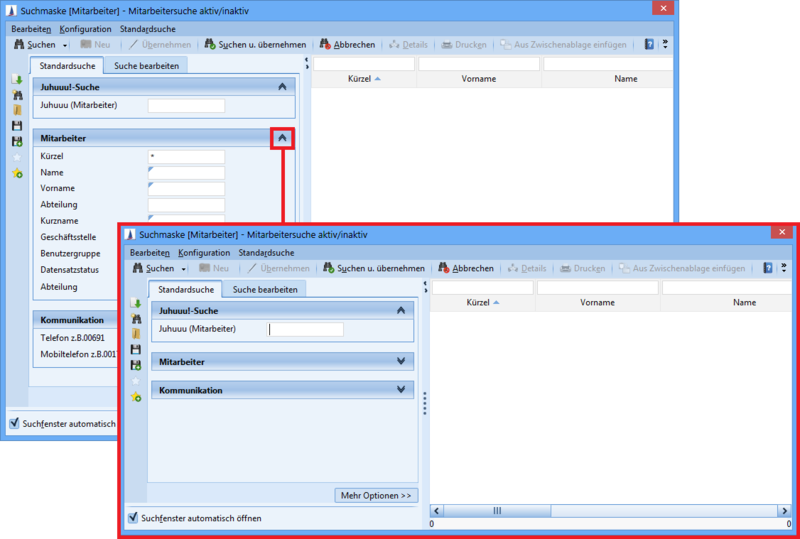
Juhuuu! search field in the standard search mask
A Juhuuu! search field can be configured and added via the 'Edit search' tab. The advantages of a text-based search, which searches based on one or more keywords simultaneously on the defined dataset (in the example: the 'Employee' entity) can be combined with the search in specific fields.
A further advantage is that several search criteria can be entered in just one Juhuuu! search field without having to make entries in the other search fields.
-
You are searching for an employee with the token XYZ from the 'Product Management' department
Input: XYZ Product Management -
Which colleague has the phone number 803?
Input: 803 -
Who is Head of Development?
Input: Head of Development
Since you can define several search criteria via one Juhuuu! search field, you need significantly fewer search fields for the default search mask.
Wildcard search
If you want to select a wildcard search, the wildcards are used implicit and should not be set by the user. In this case, it is a partial-string search.
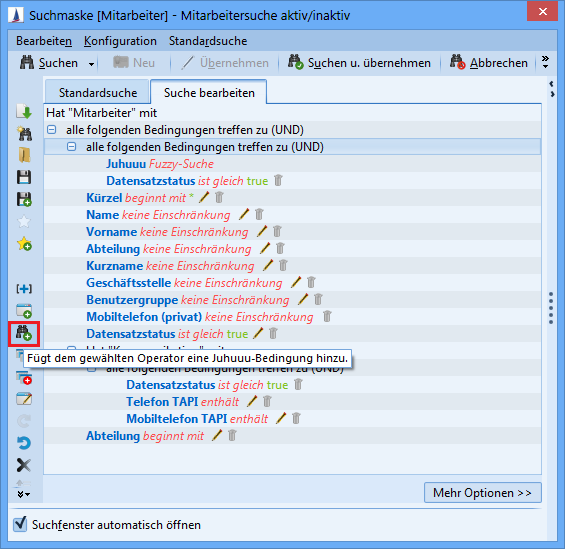
Adding is subject to the following restrictions:
-
The field can only be added to operator nodes (e.g. "all following conditions apply (AND)").
-
Only one field can be added per operator branch (entity).
-
The entity to which the field is to be added must be added to the Juhuuu! index.
Fuzzy searches can affect system performance.
Rebuilding the search index for tables updated by an interface
Structural changes to the UnindexedEntity table
-
New field priority of the type INTEGER
-
Function
The priority of a dataset to be indexed is stored in this field. Only priority 1 is entered in this column using CURSOR-CRM.
An interface can fill this field with 2, in which case these dataset are indexed downstream. This procedure is useful for changes from 10,000 up to 100,000 entries, if the timer for indexing is configured with the default value of 15 minutes. -
Example
100,000 datasets have been included in UnindexedEntity. The entries in the UnindexedEntity are processed in blocks of 10,000.
With this configuration, at least 10 passes are required to index all data, since datasets are still added via the application. The datasets created in the application are now always processed at the beginning of such a block. So it takes about 150 - 165 min until all entered data have been indexed.
For version 13.2 this functionality was patched back, but the field "ClientNo" was used there for this functionality.
-
-
New field IndexedStatus NUMBER (1)
-
Function
In this field, the application selects the datasets that it has already tried to index.
This is due to the problem of Excel files that are loaded and read into memory during indexing. These can become so large in the memory that the application encounters an OutOfMemoryException and the server is restarted. Making this selection means the server does not run into this problem, since only selected data is indexed.
In previous versions, the "Status" field was misused for this purpose.
-
Rebuilding the Juhuuu search index via UnindexedEntity
The interface can enter a dataset into the UnindexedEntity table that triggers reindexing of an entity.
This dataset must be filled as follows:
-
Pk = Entity name
-
EntityName = Entity name
-
TableTail must be filled in
If such a dataset is found when passing via the UnindexedEntity, the entire entity is re-indexed.
Advantage:
It is not necessary to write all changed datasets individually into the UnindexedEntity.
Disadvantage:
The runtime for rebuilding an index can be quite high. No other index can be updated during this time.
Rebuilding an index in a separate directory
If an index is rebuilt, you can continue reading from the old version. The index is not copied to the "reading location" until it has been re-created.
The rebuilding takes place in the NEW subdirectory of the actual search index directory.
Processing of incremental Juhuuu! indexing is configurable
On servers with a changed server setting for DEFAULT_MAX_ROW_NO=10000, the block size of the incremental Juhuu! indexing can now be configured, since this setting can cause the indexing to terminate in extreme cases.
The block size has been changed from the value of DEFAULT_MAX_ROW_NO to default 768.
If the block size is to be changed to e.g. 5000, this can be done with the following PropertyMapper statement
ORACLE
INSERT into PropertyMapper (Pk, id, property, propertyType, principal,
CustLayer, propertyValue , Active, MassData,
RightPk, CreateUser, UpdateUser, CreateDate, UpdateDate) Values
('disableInstallationMaskLogic','/de/cursor/jevi/server/system/search/simplesearch/IndexHandler$!!$luceneIndexBlockSize',
null, 'SYSTEM', null, 'CN', '5000', 1, 0,
'RIGHTTEMPLATE', 'TECH_USER', 'TECH_USER', sysdate, sysdate)
MSSQL
INSERT into PropertyMapper (Pk, id, property, propertyType, principal,
CustLayer, propertyValue , Active, MassData,
RightPk, CreateUser, UpdateUser, CreateDate, UpdateDate) Values
('disableInstallationMaskLogic','/de/cursor/jevi/server/system/search/simplesearch/IndexHandler$!!$luceneIndexBlockSize',
null, 'SYSTEM', null, 'CN', '5000', 1, 0,
'RIGHTTEMPLATE', 'TECH_USER', 'TECH_USER', GETDATE(), GETDATE())
If the set value is invalid (less than 1 or greater than the DEFAULT_MAX_ROW_NO or no number), the default value of 768 is used.
Lucene index can be swapped out to a mass data server
The structure of the Lucene index can be shifted to a report server. The configuration is done via the Admin Console.
-
Stability:
The index structure can run on OutOfMemory when extracting text from documents. Especially when extracting text from Excel files (the only ones that have caused problems so far), you can't say reliably how much storage space a certain file needs to extract text.
If the operation is moved to another server, it will also get stucked with OutOfMemory, but this will have less dramatic consequences for the users' work. -
Performance:
The complete reconstruction of the index requires considerable resources on the application server. By shifting this load to the alternative application server, it is removed from the "main server".
Assumptions/Prerequisites/Framework conditions
-
An alternative application server must be installed and configured
-
The "Mass data server" module must be activated
-
The Lucene index should be able to be built on the alternative application server, if one exists in the system.
-
If no alternative application server is configured, indexing takes place on the main server
Details for the configuration
If an alternative application server is configured and the usage setting is enabled
-
The initial indexing starts on the alternative application server
-
The manual indexing of entities starts on the alternative application server
-
The incremental indexing starts on the alternative application server
-
The index can be read by all other servers in the system
If the alternative application server was restarted, it may happen that a job was currently in progress and now has the status "PROCESSING". The status "PROCESSING" should therefore be checked and reset in the initialization timer of the alternative application server so that all jobs can be done continuously.
-
The initialization timer is also executed on the alternative application server
-
However, this only checks for jobs that are still running
-
These jobs are reset in status and execution is restarted.