General modeling
Business and implementation BPM model use the same language and methodology for modeling. They differ in terms of content and the characteristics of their various elements. While in the business model simplicity and documentation are at the forefront, the focus of implementation models is on workflow capability of the elements and therefore on their correct configuration and syntactic correctness.
Multiple pools can be modeled in the business model. In an implementation model, you can specify details for exactly one pool.
Modeling recommendations
The aim of modeling recommendations is to facilitate a collaboration between multiple process designers, to increase transparency and clarity and to reduce error risk.
General best practices
-
Practice-oriented reduction of the symbols uses in order to reduce complexity (less is more!)
-
The courage to document default workflows and not each and every single exception!
-
Get some experience in iteratively refining processes - in other words: don't try to implement everything at once...
-
Use cooperative models like conversation and choreography only after you have familiarized yourself with process modeling
-
Define company-internal modeling conventions (sufficiently precise, with illustrative examples)
-
Go to as much detail as necessary with as much clarity as possible, i.e. in the implementation model:
-
Model default workflows,
-
only document exceptions!
-
-
A consistent path from the start event to the end event must be modeled across the entire process workflow (the "process token" must be able to flow end to end)
Layout
-
Limited to "one DIN A4 page" - check the sub division into sub processes if that is exceeded
-
No symbol overlays, especially in sequence flows
-
Sequence flows run from left to right and from the top down
-
Tasks have exactly 1 incoming and 1 outgoing sequence flow
-
Sequence flows branch off at right angles
Naming
-
As precise and descriptive as possible
-
Unique names for each element
-
Processes: Nouns (e.g. application processing)
-
Events: Object and past participle (e.g. demand identified)
-
Tasks: Verb and object (e.g. log application)
Process structure
-
Modeling responsibilities (pools and lanes)
-
Exactly one start event, at least one end event
-
Start event: exactly one outgoing sequence flow
-
End event: exactly one incoming sequence flow
-
Sending events = tasks, receiving events = news
-
Hierarchical use of sub processes (no circular argument)
-
No merging or branching out via tasks - only via gateways
-
Gateways: either merge or branch out
-
Branching gateways represent questions and the relevant answers can be found at the outgoing sequence flows
-
Each merging gateway has at least two incoming sequence flows
-
Each branching gateway has at least two outgoing sequence flows
-
Each branching gateway has exactly one outgoing default sequence flow
User interface for business and implementation modeling
A graphical user interface is provided for modeling.
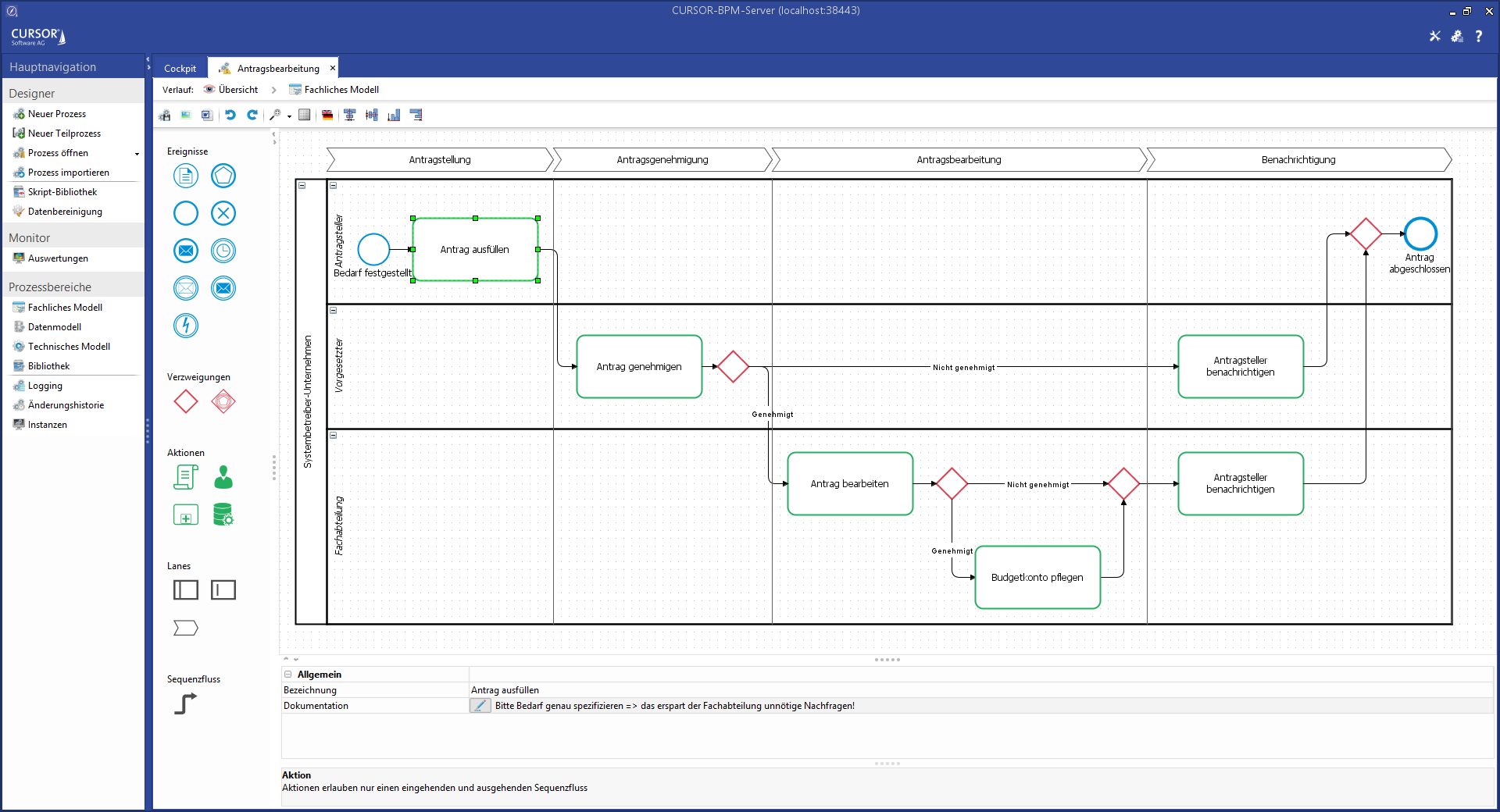
All available elements are listed on the left of the palette. These elements can be dragged and dropped onto the modeling area.
The position of the sub divided areas of the palette and the cell properties are saved for each model type when the user exits the view and reloads when the view is reopened.
General operation and procedure
The various elements are edited via drag and drop or via editors, as is the case for documentation. The editors utilize available space to display as much information as possible. Navigation therefore occurs via the "Path" line. There, you can click on e.g. ![]()
You will be asked if you want to save your progress when navigating to a different location. Clicking the buttonApply will (buffer) save changes and clicking the button Apply and close will bring you back to the model. The overall process is saved by clicking the "Save" button in the process overview.
Element editing
Each Element has a name and can be described in more detail via the property Documentation. The name can be changed either via the property field or by double-clicking the element in the process chart. The description allows simple HTML formatting like <b>,<i>,<br>. Special characters like <,>,& must be described as HTML entities with <,>,&.
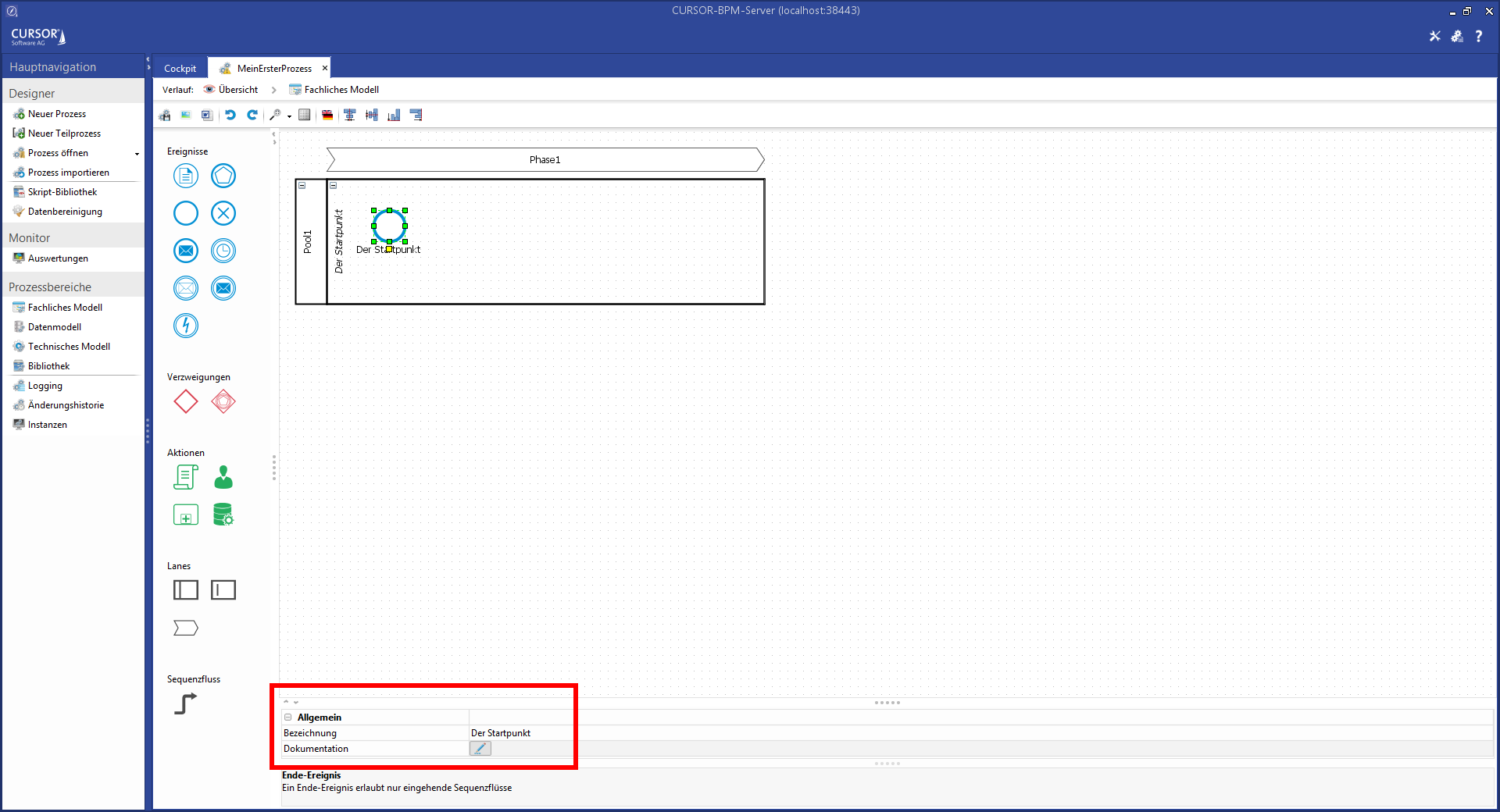
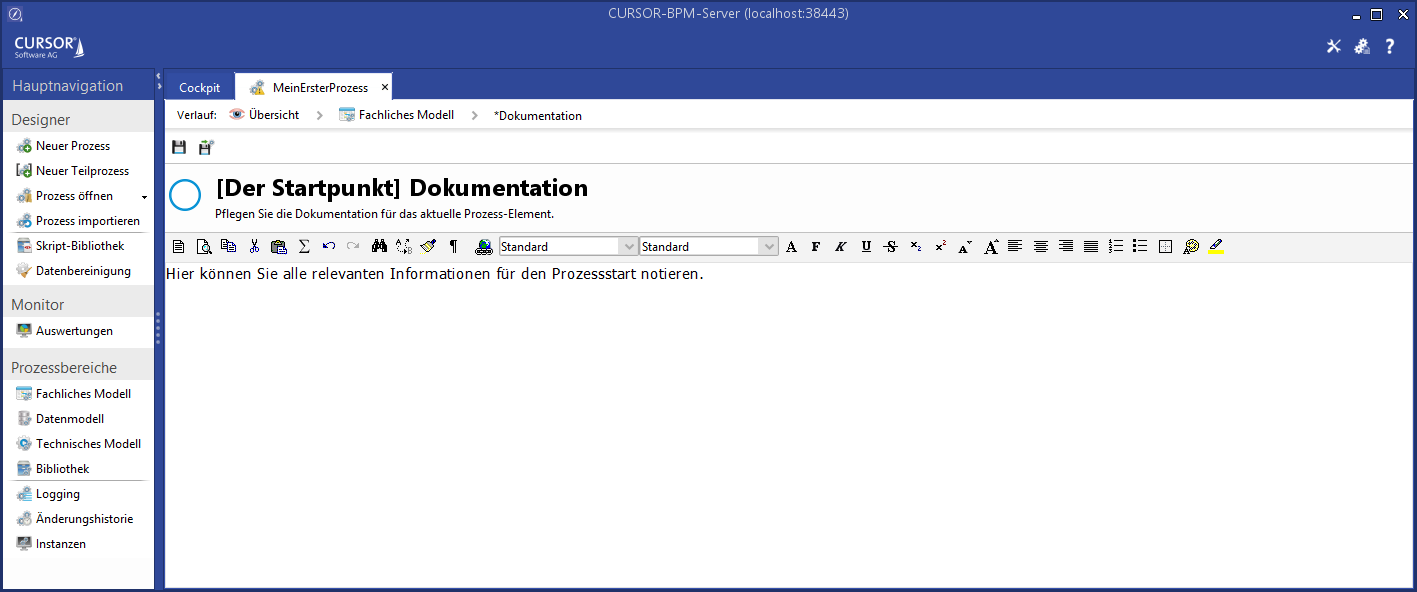
Clicking the button Unknown Attachment in the field Documentation stores the documentation in a HTML-capable editor pane:
Elements from the palette can be drawn and described via drag and drop.
Hint
Use meaningful and clear names to help understand the rough process from within the process graph. Use an object and a verb to describe the activities.
Process flow
Connect the various process elements to visualize the process workflow. Press and hold the SHIFT key and move the cursor over the first element to change its appearance. The two elements are connected, once the second element, which is to be connected, is displayed with a green border.
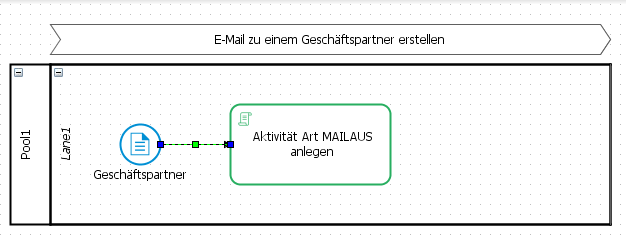
This method allows the quick generation of multiple interconnected activities.
A later change of the flow can be effected by highlighting the flow element and moving the start and end point to another element. You can also influence the line of flow by moving the green marking of the flow element:
Undo changes
Model changes, like the insertion of new elements or the movement or connection of elements and edges can be undone via the buttons ![]()
![]()

Cell alignment

The alignment of selected elements in the model can be changed via the separate button bar. Elements can be moved via the arrow keys.
Internationalization
CURSOR-BPM ensures that you can model and edit your processes in all supported languages. CURSOR-BPM will open in the system language set by the user or in the language with which the user has started CRM. That ensures that each process designer can work in his preferred language. An additional option allows cross-language modeling and execution, so that you can switch languages for each process element or process. That means you continue to work in the set GUI, but process users may see the process in another language.
Internationalization of process elements
![]()
Both process models contain the button Internationalize. It allows the storage of a translation for the currently selected element. A table will open in which the name and the documentation of the selected elements is displayed and where these can be edited.
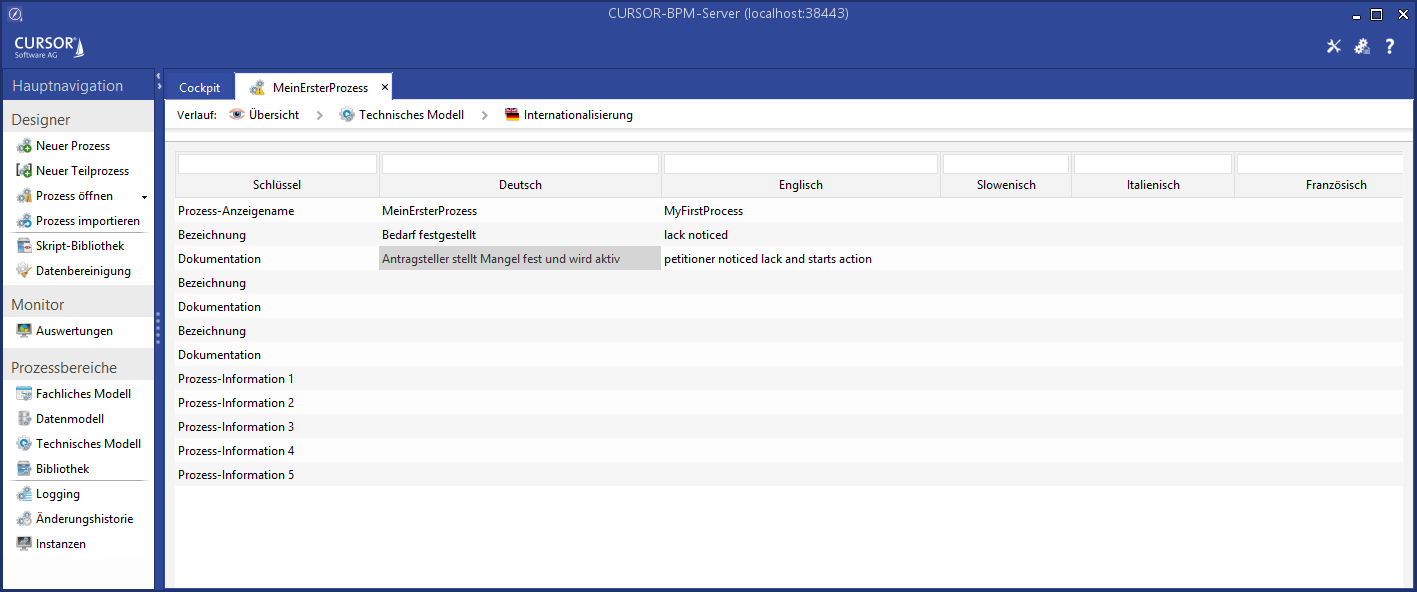
All process elements will be displayed if no explicit selection was made. This method can also be used for translating the name of the process.
Modeling in the implementation model
![]()
Modeling in the implementation model is for the most part analog to the business model. There are, however, some additional elements in the palette, which offer further configuration options and editors. Please read the relevant chapters about these elements for more information.
If you have started with the business process modeling, then the business model can be used as the basis for the implementation model. This can also be done in retrospect if you have already started with the modeling of the implementation model. Applying the information via the button Generate from concept model will overwrite the current progress. The copy function will do all the basic process designing for you. The first, i.e. the top-most pool, will be applied from the business model to the implementation model. All properties outside the name and documentation of the individual elements will have to be addressed in detail afterwards and you may have to add more elements. Please note that only one pool is permitted in the implementation model, which is why only the first, i.e. the top most pool from the business model can be applied during the copy process.
Deploy
Another difference between the business and implementation model is that the implementation model represents the basis for process deployment. The created process must be activated in the CRM system via the button Deploy (from within the implementation model or the process cockpit). Once deployed successfully, the process will be ready for use in the application. It will start as soon as the relevant start condition is met. The process status will be visible in the process overview on the right of the screen.

All elements form the repository will be copied for the process implementation version. That means that any changes to searches and masks in the repository will have no impact on running process instances. These changes will only be applied at the time of next deployment for the new process version. In contrast, changes to the script library directly affect the process scripts.
The validity of the process model is checked before it is published.
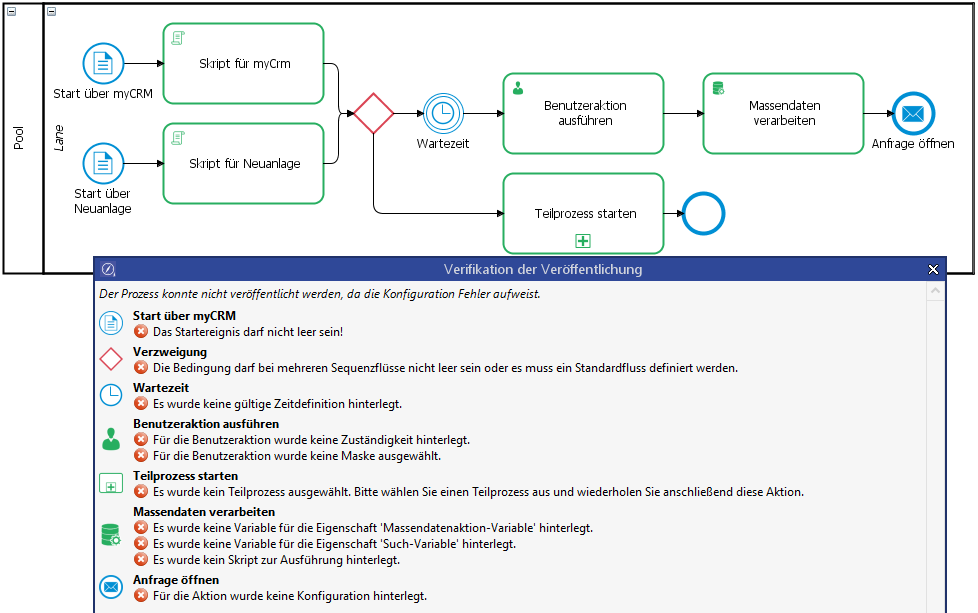
You can use the dialog to mark the incorrect action in the process model. The process can only be published when all errors in the process model have been corrected. There is no check for valid definitions of process variables, since this can differ in the runtime behavior of the processes.
Processes imported via the customizing transport are deployed automatically in the data target.
Any process that is not to be used any more can be deactivated. Started process instances can be run to the end. The process will, however, not be able to start again.
Delete
![]()
Any processes that are no longer needed can be deleted by clicking the Trash symbol. The process will then be removed from the system, provided it was deactivated beforehand and there are no other instances of the process running any more. We recommend exporting any process for backup reasons before deleting it. You can then re-import it at any time as needed or at least be able to save a complete process documentation. All the "knowledge" contained in the process will always be accessible again.
Basic information about scripting in user tasks and scripting actions
To ensure correct scripting in user tasks and in script tasks, you need to be familiar with concepts for data types, validity ranges for variables and assignment options for sub range information.
Caution
Support help is basically only available for scripts when the utility classes provided by CURSOR and the Java standard data types and methods are used. CURSOR is not required to provide support for the use of third-party libraries. CURSOR cannot guarantee a release-safe application of any internal objects and utilities of the CRM environment referenced in the script implementation that are not deployed via the script documentation for updates or new releases.
The context of workspaces, entries, containers and values
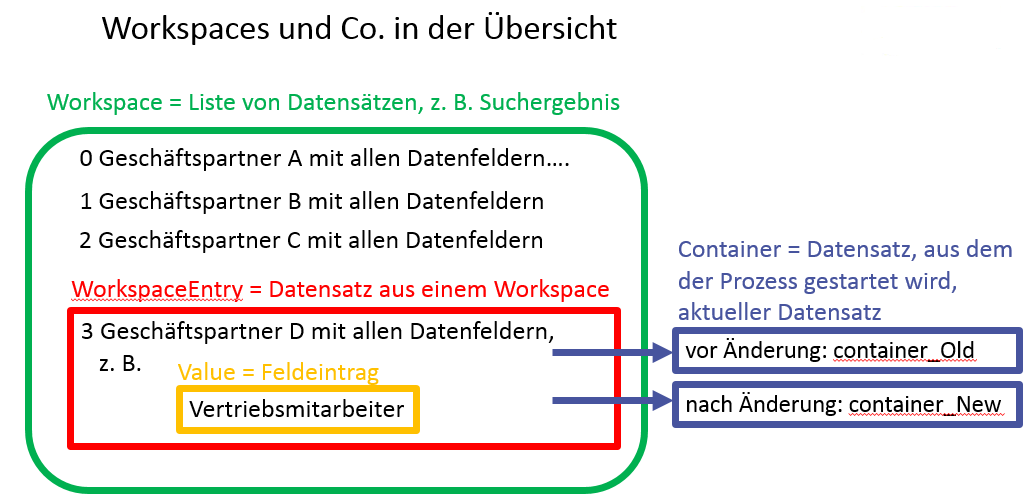
Differences between process and action variables

Definition of entity assignments in sub sections
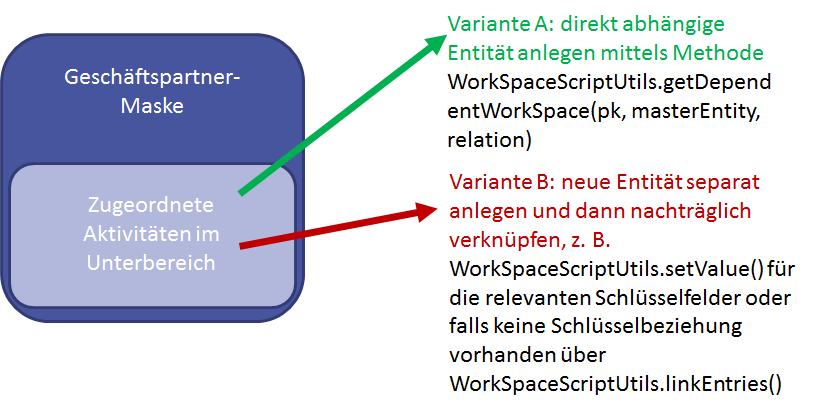
Synchronizing data in CRM and processes
Process variables can contain datasets from CRM. These datasets are loaded from CRM, but can become obsolete over time if data is not updated from the CRM system. This problem can occur if a dataset is read using a BPM script task and is transferred to the user task. If the user doesn't process the user task until a few days later, then the dataset in the process variables will be obsolete, i.e. current changes in the dataset will not be visible in the user task. This issue also applies to incoming intermediate events, which could erroneously access obsolete data in subsequent processing.
These datasets are managed as variables of the data type IContainer. In the variable definition, these variables can be marked with the option auto synch. Each user task allows the automatic update of dataset variables when the task is opened, so that the user will always have the correct data displayed. The option auto write can also be activated to write any changes by the user directly to the CRM system. Auto read/write is applied to all available IContainer variables of the process instance. Only those datasets will be saved that had data changes during the process. The data update mechanism is also available for intermediate events.
Handling update conflicts
Update conflicts and available solution options
Any data changed during a process execution can be written back to CRM via script methods. This may result in update conflicts when working in CRM, e.g.:
-
when relevant data in CRM were changed in the following time frame: after loading the original data for a process or before process data is saved back to CRM or
-
if a dataset is edited by two users simultaneously.
Update conflicts can occur specifically if several hours/days pass between the loading of the data and the saving of that data, e.g. if they occur in separate script tasks that were interrupted by a user task. If that is the case, then the IContainer loaded for process execution can contain obsolete data: i.e. changes from another user or another action are overwritten during loading without confirmation request.
Schematic visualizations regarding the context of data maintenance in processes and in CRM can be found in a separate chapter of the manual Technical framework conditions / DataMaintenanceBetweenBPM-ProcessandCRM.
As of version 15.1, the update date in the dataset will be compared with the current value in the database. An UpdateConflictException will be thrown if the database value is more recent. This error can be resolved by the user via the update conflict dialog in a user task by defining the data for writing as follows:
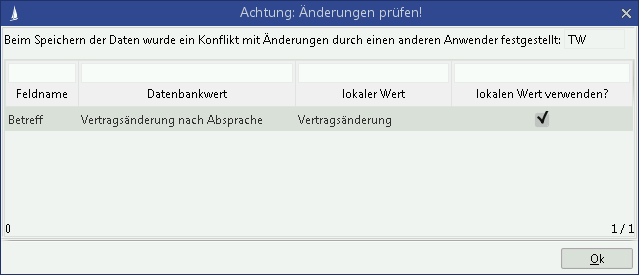
With an acknowledgement ("OK"), the entire "Save" script will be run again, but this time with the relevantly updated dataset.
Scripting prerequisites for the correct handling of update conflicts
Correct and complete load of the relevant datasets
The mechanism for recognizing update conflicts requires that the dataset was loaded correctly (in the sense of completely) from IScriptWorkSpace to the process scripts before it is written. Changes in a dataset will, after all, only be saved if the changed fields exist in the loaded dataset. Similarly, CRM must also load the dataset completely (see also list view and detail view) in order to save data.
The following example shows a programming in which a dataset was not loaded completely, which means it can later not be saved correctly:
incorrect programming
IContainer entry = WorkSpaceScriptUtils.searchEntryForRead("abc", "Activity")
WorkSpaceScriptUtils.setValue(entry, "Subject.Activity", "abc")
...
IScriptWorkSpace workSpace = WorkSpaceScriptUtils.searchEntry("abc", "Activity") //der Datensatz wurde nicht vollständig geladen!
WorkSpaceScriptUtils.saveEntry(workSpace, entry) //das Speichern wird nicht korrekt funktionieren
The correct script would be as follows:
correct programming
IScriptWorkSpace workSpace = WorkSpaceScriptUtils.searchEntry("abc", "Activity")
IContainer entry = WorkSpaceScriptUtils.getEntry(workSpace, 0) //der Datensatz wurde vollständig geladen!
WorkSpaceScriptUtils.setValue(entry, "Subject.Activity", "abc")
...
WorkSpaceScriptUtils.saveEntry(workSpace, entry) //das Speichern wird nun korrekt funktionieren
Only in this case, changes to IContainer will now be forwarded correctly to the database.
Call-ups of "WorkSpaceScriptUtils.saveEntry" only with an allocation of the return container for updating of the reference data stored in the process
The new recognition function for detecting update conflicts will cause problems in existing processes if they don't work with current process reference data needed for the detection of update conflicts when saving to the CRM database:
The following process graph shows a model for a workflow with potential update conflicts, which will be explained in more detail below:

The following script extract shows that the dataset is being loaded to "Preparation":
Preparation
IContainer entry = WorkSpaceScriptUtils.searchEntryForRead("abc", "Activity")
ProcessUtils.setVariable("entry", entry)
Next, the dataset is modified as part of a user task:
data mask
completetask()
{
WorkSpaceScriptUtils.setValue(entry, "Subject.Activity", "abc")
...
}
The changes from the user task are then saved:
Save changes
IScriptWorkSpace workSpace = WorkSpaceScriptUtils.searchEntry("abc", "Activity")
WorkSpaceScriptUtils.getEntry(workSpace, 0)
WorkSpaceScriptUtils.saveEntry(workSpace, entry)
There will not necessarily be an update conflict during the first run-through (i.e. when the data is first saved to the CRM database by the process). A conflict may, however, arise if the dataset was edited by another user in the interim. This issue can be resolved via the update conflict dialog as described above.
However, if the process requires some rework, then there will always be an update conflict during the second run-through because of the mentioned scriptings.
This problem occurs, because the dataset of the process was updated in the database during the first save. This change in CRM data was, however, not written back into the process. The process execution therefore only knows the version from the first data load as its original data. A second save of date from within the process to CRM would therefore trigger the recognition of an update conflict, because the dataset versions at the start time will be compared by the process with the current CRM data (which was changed by the process in the meantime).
It is therefore important that the data known to the process (reference data for the recognition of update conflicts) is updated as well. That can be done by reassigning the return value from the method WorkSpaceScriptUtils.saveEntry back to the IContainer variable, so that the process variable is updated for further use.
The following scripting would have to be done for this example:
Save changes - correct!
IScriptWorkSpace workSpace = WorkSpaceScriptUtils.searchEntry("abc", "Activity")
WorkSpaceScriptUtils.getEntry(workSpace, 0)
IContainer newEntry = WorkSpaceScriptUtils.saveEntry(workSpace, entry)
ProcessUtils.setVariable("entry", newEntry)
This will ensure that the process execution will not recognize its own data changes as an update conflict.
In order to recognize these issues before the update to v15.1, processes can be verified via the task ![]()
The validation (as of 14.1.09) searches for call-ups of WorkSpaceScriptUtils.saveEntry without an assignment of the return container.
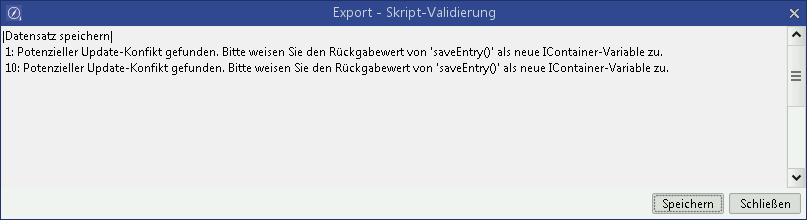
This verification will also occur during the update to v15.1, which means that any processes potentially at risk will be displayed by the update tool and will be additionally be added to the log of the update routine.
In addition to the mechanisms ahead of and during the update to v15.1, script validation will also be done every time a script task is saved.
Contexts of data synchronization between process and CRM and handling of update conflicts
In order to further minimize update conflicts, dataset variables should be updated in the process as often as possible. When a user task updates the dataset variables for processing upon opening, then the process will automatically work with the latest data from CRM. Prerequisite is that the variable of type IContainer has the option Update automatically selected and that the user task has the option auto read enabled. When the user task is opened, all dataset variables defined in the process repository and validly filled at runtime are updated. And not only those currently needed for the user task. It is important to note that the dataset variables can contain data from other entities, e.g. from a search or via manual settings. Any such data will be discarded when an automatic update takes place.
The automatic write process at the end of a user task is applied to all available dataset variables, not just to the dataset that has just been edited by the user. Datasets that contain no changed data will not be updated. This too may result in an update conflict if the dataset to be written was edited by another user simultaneously or the option auto read was disabled. These conflicts can be resolved via the update conflict handling dialog. This dialog will appear multiple times if multiple dataset variables are affected.
Handling of long-term transactions
Depending on process requirements, it may make sense to initiate process with a time delay, e.g. to give database actions of the previous process enough time to be completed and to allow the new process to access the changed data in the database. This time delay option has now been added to the ProcessUtils.startProcess method, so that the following parameters are now available:
-
processId- the ID of the process -
variables- mapping with variables -
isAsychonous- TRUE the process will be started in asynchronous mode. -
delay- time offset in milliseconds for the asynchronous start. The default for a safe transaction completion is 1000 ms. This parameter is optional.
Example:
ProcessUtils.startProcess("myID", map, false);
Linking masks and searches to a process
Description
Masks and searches can be used in multiple processes. To find out, whether a change will affect other processes, a link between the process container and the mask/search must be established in the database. Process searches should furthermore be clearly marked as such, which is already done for masks.
Marking searches as process searches
The ExtendedSearch table is expanded to include the SearchType field. This field can be populated with an Enum value (key). PROCESS stands for BPM searches in this case. The standard application cannot open a BPM search for editing; this can only be done via CURSOR-BPM. All searches in CURSOR-BPM are created automatically as BPM searches. Only process searches can be added to a process in the repository. These automatically become system searches (remove call-up when saving).
Linking external data
A linking entry is written to the table CustRepository (or to a table of the customizing transport) when masks/searches are created or added. This entry must be removed when the process is deleted. Masks/searches that are being edited will be checked for multiple use in other processes. If a further use is detected, the change can be applied to all processes or canceled (after confirmation by the user).
Processes modified by the change get the status 'externally changed' and are get the entry for the changed search in the change log.
Historicizing process masks and searches
Masks and searches will now be loaded for the exact process version in all script methods and functions in BPM masks.