BPM and transactions
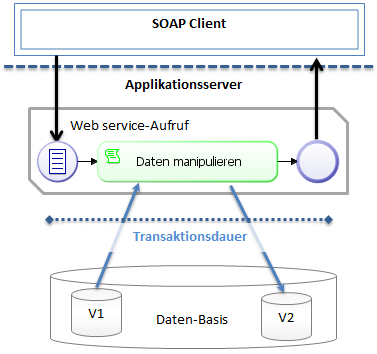
Working with processes - event-triggered or with user interaction - requires a special understanding for the transaction-relevant workflows in BPM. General transaction management is done by the application server. A new database transaction is initiated when a server function is called up by the client, externally by a web server or a time-controlled action on the application server. All data manipulated in this transaction will only become visible for other database transactions, once the transaction is completed.
The transaction will only be completed, when the called-up server function returns a result.
Automated transaction management
That is why a process is generally executed in multiple transactions. Transaction limits are defined by wait states. These include
-
User tasks
-
Message intermediate in events
-
Timer intermediate event
-
Transaction-interrupting intermediate events (new as of 15.2)
A transaction will not necessarily start at the time of process start or end at the time of process end. Since a process can be called up in the context of server functions, the transaction will start at the time of server function start and will only end with the return result of that function. The execution of an event-based process, e.g. saving of a dataset, occurs within the transaction of the storage process.
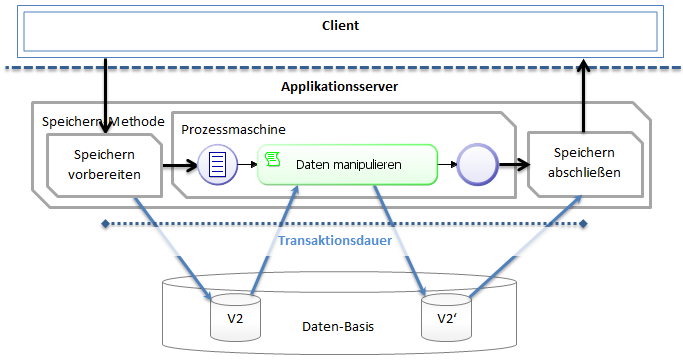
The behavior differs for manually started processes. The transaction will then start at the time of process start and end when the process ends or when the first process-interrupting wait state occurs.
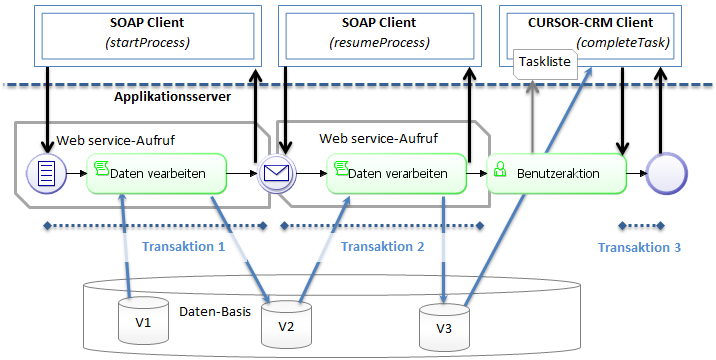
Data changes are carried out in sequential transactions if the process contains multiple wait states, i.e. user tasks or intermediate events. The length of the wait status determines the time when a new transaction is started, triggered by the continuation of the process. The wait status can be a few seconds or several days in length, depending on configuration and/or user interaction. Opening a user task will not start a transaction. A new transaction will only start, once the user completes the task. The same applies when the process is continued on the basis of incoming messages via email or web service.
The default transaction time is set to 5 minutes by the application server. That means that all server-side actions and the data processing in script tasks must come to max. 5 minutes in total, as otherwise the entire transaction including all data changes will be rolled back. The transaction will also be canceled if an error occurs during process execution.
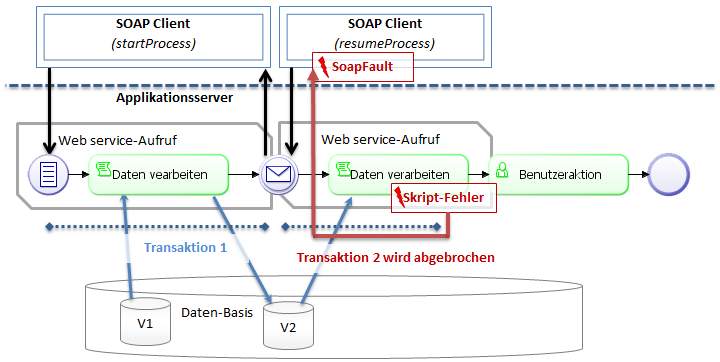
All data changes carried out during this transaction will be rolled back. Any changes from previous transactions will remain intact.
Transaction intermediate event
A transaction time of 5 minutes is insufficient for the processing of mass data. A running process transaction must be interrupted by a transaction intermediate event in order to specify a longer transaction time in the process. The server call is ended by the completion of the running transaction and control is returned to the client. The transaction intermediate event effects an automatic asynchronous continuation of the process on the application server in the background.
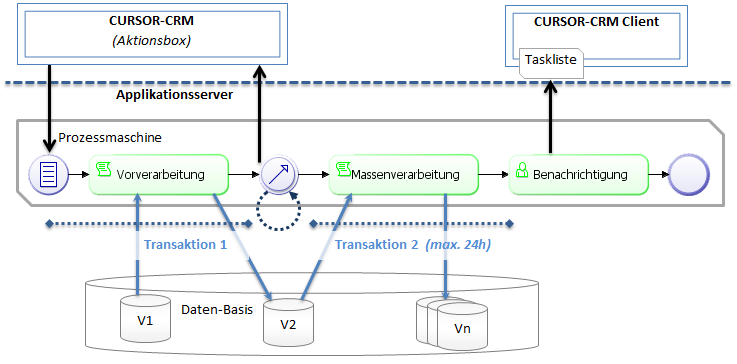
The intermediate event allows the initiation of a new long-tern transaction. The transaction runs for a maximum of 24 hours.
Any subsequent script tasks can now process mass data as part of a transaction. In case of very large data volumes, it makes sense to sub divide the processing into data blocks.
Various tricks have been used to allow the processing of mass data in older versions (15.1, etc.,), none of which function reliably. The validation of processes via CURSOR-BPM was therefore extended to recognize these workarounds.
Timer intermediate event without specified time
The process is interrupted analog to the transaction intermediate event and is continued asynchronously. The problem here, however, is that the continuation does not wait for the transaction end of the interrupted process.
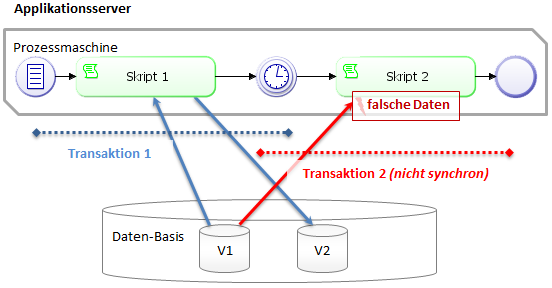
The transaction before the intermediate event will not persist in the database as yet and the new transaction after the intermediate event will not be able to reliably access this new data.
Asynchronous process start in script tasks
Another process can be asynchronously called via ProcessUtils.startProcess(). This is used in part to actively call up the own process repeatedly in a loop and to therefore work off mass data block by block. The asynchronous start waits one second in the standard. This time may, however, not always be sufficient for the previous process to run its transaction to completion. That means that the new process will not be able to access updated data.
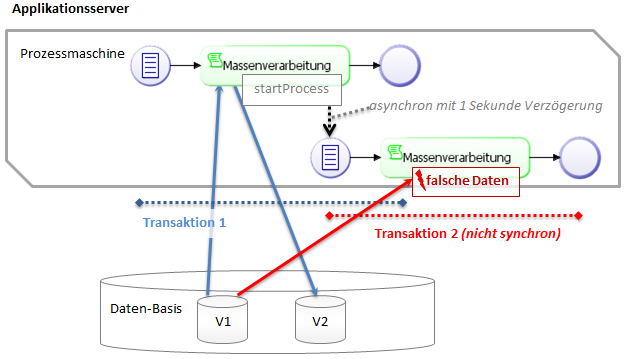
Asynchronous processes should therefore only be started to trigger other tasks in the process that don't need to access data from the process initiating the call. Should data from the previous process be needed, then that data should be forwarded to the process call directly in the form of parameters. Alternatively, the process should be started synchronously, which will force it to access the same transaction.
Self-terminating user task
In order to force a transaction completion, a user task was used in some cases that would self-terminate when it opened. These tasks must now be replaced by the new transaction intermediate event.
script for the user task
initTask() {
TaskUtils.completeTask();
}
Error handling in asynchronous runs
When a process is started asynchronously and encounters an error during runtime (without interruption), then the error status will only be visible in the log, because the calling entity is not waiting for a process response. In an asynchronous process, the call must be repeated.
For asynchronous intermediate events, it depends on the definition, whether or not an instance can be continued again after an error in the process continuation. In case of incoming mails, these mails can be imported again. In the case of a web service, the call can also be repeated with corrected data.
It only becomes problematic for timer intermediate and transaction interrupting events. These events are executed internally in the server. That is why the process instance cannot be continued by any user or administrator. The process engine will initiate a maximum of three tries to continue the timer intermediate event. In the transaction intermediate event there is a setting (Abort on error), which causes a process termination in case of an error. Thus, a process controlled by a timer could be restarted by the timer after it has been aborted.
Access to data changes in a transaction
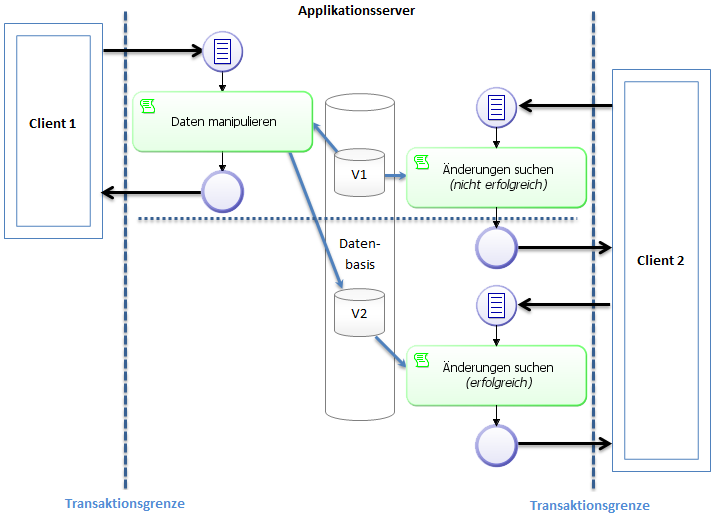
Up to version 15.1, not all changes in the database could be found via a search, even though the user would be in the same transaction, e.g. in the same script task. Affected are
-
WorkSpaceScriptUtils.saveEntry
-
WorkSpaceScriptUtils.deleteEntryAt
-
WorkSpaceScriptUtils.setRightTemplate
The data changes from these methods were not transferred directly to the database and the system was therefore unable to evaluate them via an SQL search. In the standard of the application server, data changes are maintained in a separate cache and only flushed to the database at the end of the transaction. New entities, on the other hand, become visible in the database transaction immediately and will not be kept in the application server cache.
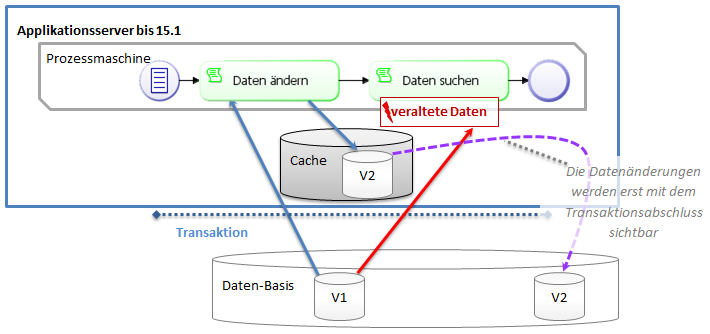
The behavior of this method was modified for version 15.2. With each call, all changes remaining in the application server cache for the current transaction will be flushed to the database immediately (Keyword: Explicit flush). That means that data changes can now be evaluated directly via an SQL search.
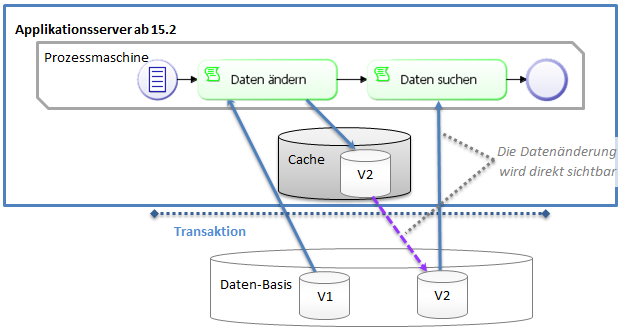
This makes working with database calls in all process scripts a lot easier.