So that it is immediately apparent whether datasets are completely filled with the most important information, each dataset has a quickly visible, visualized score. This shows what percentage of the most important information is filled in the present dataset. If, for example, only 20 percent of the relevant data is available for a dataset, it is immediately obvious that rework is necessary or that missing information should be added.
This "important" information is marked via a field property "Relevant for data quality". Required fields are automatically marked as "Relevant for data quality".
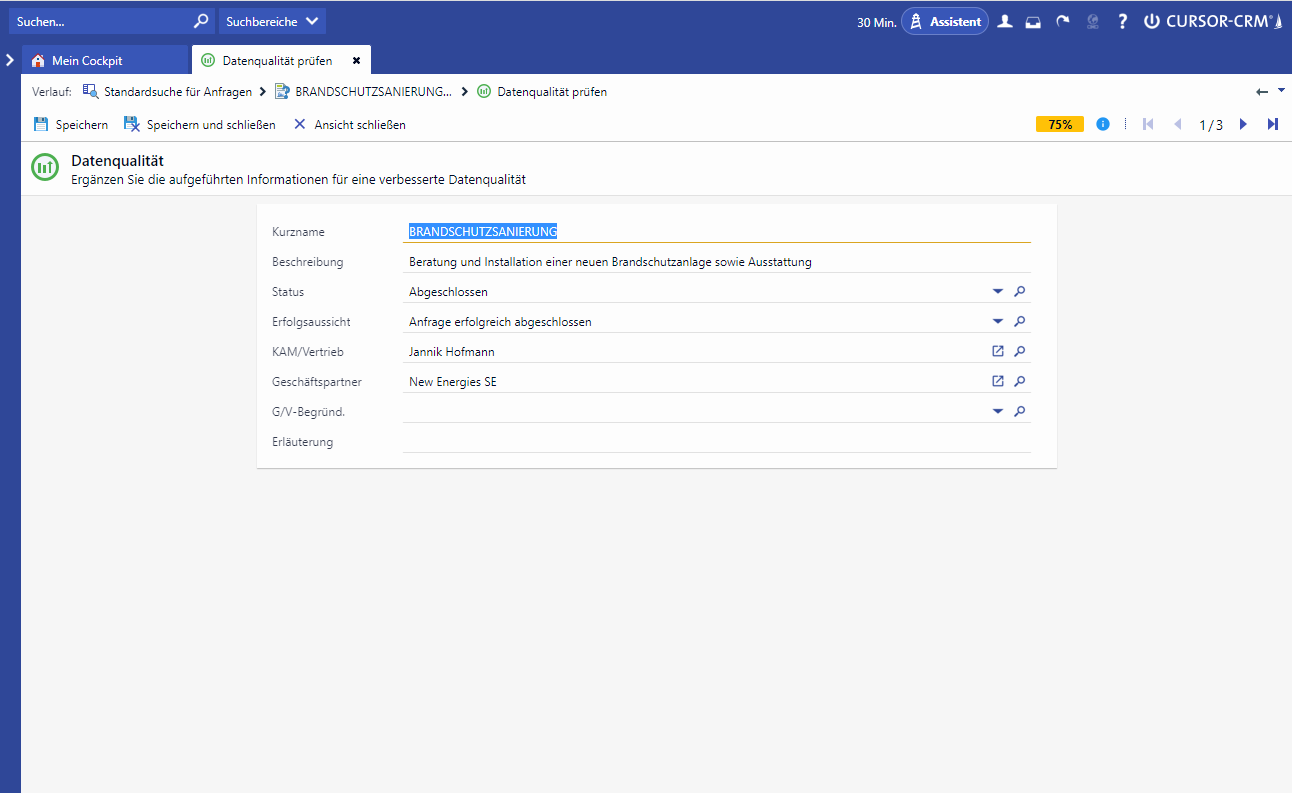
In order not to have to search for the relevant fields on the mask, you can display the important fields by clicking the button. In the dialog all relevant fields are always displayed, so that the actuality of these fields can also be checked.
The data quality display is updated every time a value is changed, either by the user or by the mask script. This behavior applies to all views in which the data quality is displayed.
Datasets with a certain data quality can be searched for specifically, e.g. "Show me my contact persons whose data quality is below 70%". Data quality can be added as a search condition in searches. However, the display of data quality in search result lists always refers to the data quality of the search result dataset, not to any inserted data quality search condition in relations of the underlying entity.
Data quality can thus also be evaluated, e.g. the average data quality of all business partners in a specific customer segment within a KPI tile. For the entities business partner, contact person, requests, quotes, projects, contracts and inbounds, a few default fields were marked as relevant for data quality.
If a field is marked as "relevant for data quality" and there is an inactive dataset in this field (= invalid lookup field), it is evaluated as "not filled" in the calculation.