2026.1
Modell-Konfiguration
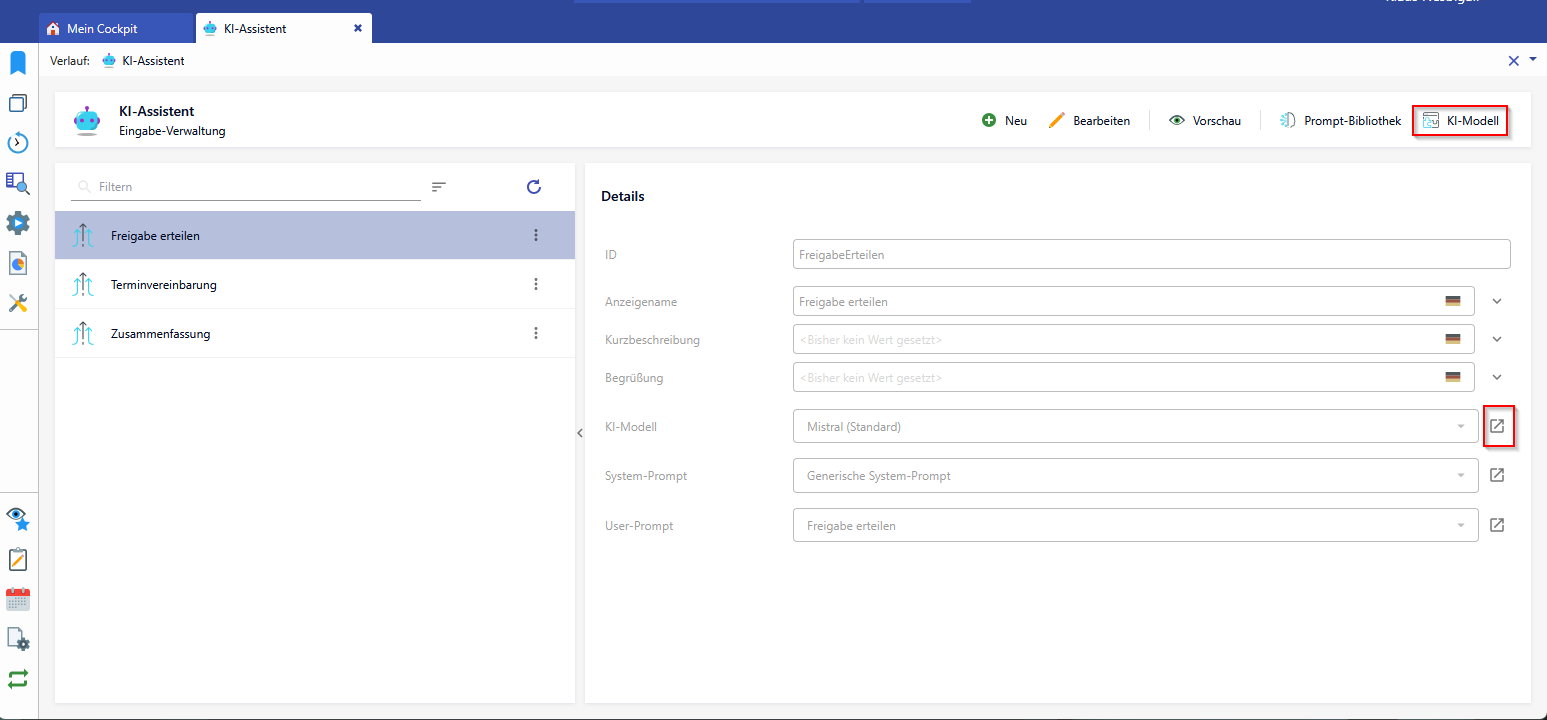
Über den Bereich KI-Assistent gelangt man über den Button oben rechts oder - sobald im KI-Assistenten ein Eingabe-Datensatz verfügbar ist - über die Verlinkung im Nachschlagefeld in den Bereich KI-Modell.
Allgemeine Informationen
Mit der Version 2026.1 wurde die zentrale Bibliothek Langchain4J eingebunden. Dies bringt den Vorteil, dass neue Modelle mit dem Release beim KI-Provider sofort verfügbar sind.
Über den Bereich KI-Assistent gelangt man über den Button oben rechts oder - sobald im KI-Assistenten ein Eingabe-Datensatz verfügbar ist - über die Verlinkung im Nachschlagefeld in den Bereich KI-Modell.
Es können verschiedene Einstellungen zum Modell konfiguriert werden:
Felder
-
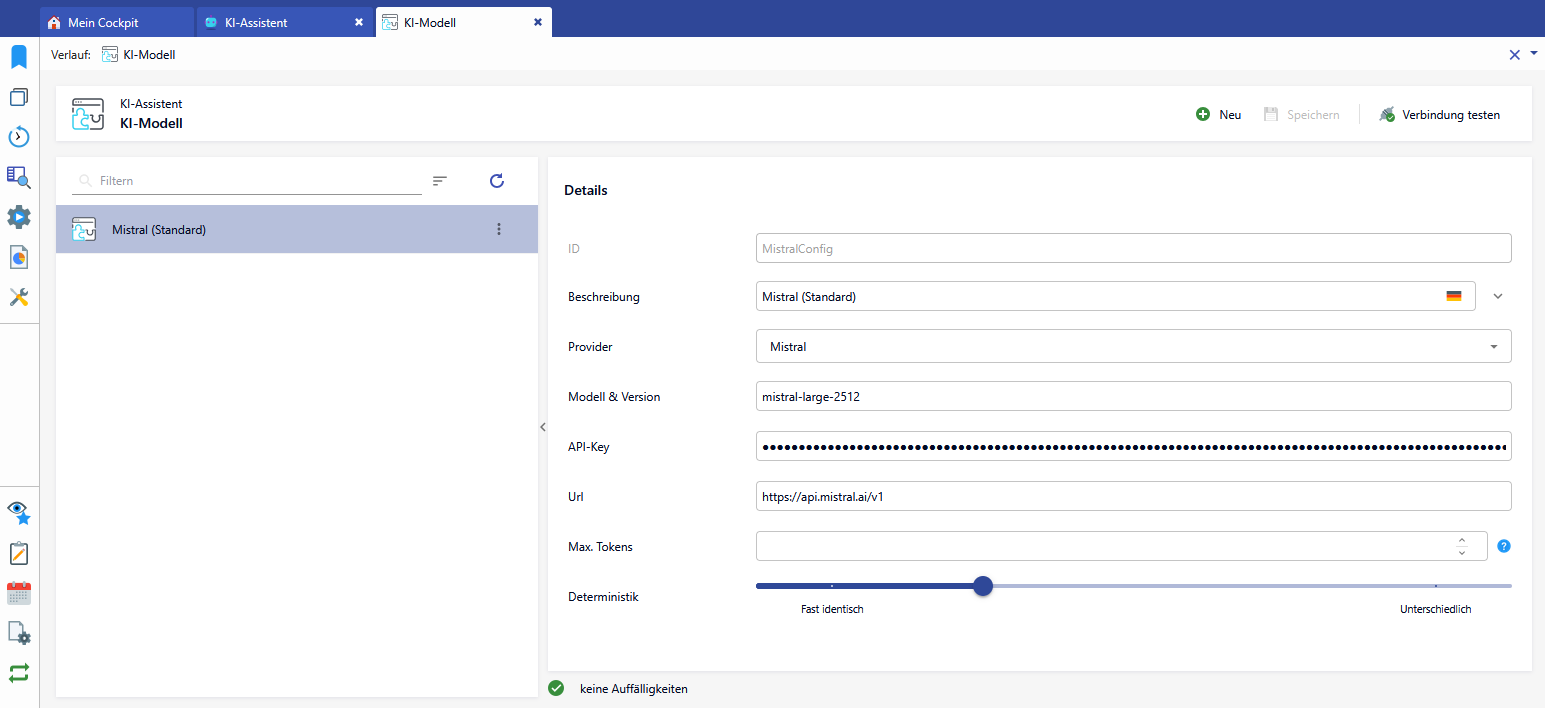
ID: Eindeutiger Konfigurationsname (insbesondere zur Verwendung in BPM)
-
Beschreibung: Internationalisierter Name der Modell-Konfiguration (wird z.B. bei der Auswahl innerhalb der Eingabe-Verwaltung angezeigt)
-
Provider: KI-Anbieter. Folgende Provider sind verfügbar:
-
Mistral
-
OpenAI (oder OpenAI kompatible Provider): Dies muss in der Dokumentation näher beschrieben werden.
-
Azure 2026.1
-
-
Modell & Version: Freitextfeld für das Modell und die Version. Der Tooltip bzw. das hinter dem Feld wird entfernt.
-
Migration:
-
Zuvor war in dem Feld "Modell & Version" Schlüssel hinterlegt. Um dies nun flexibler zu gestalten, wurde dies in ein Textfeld geändert, so dass hier neue KI-Modelle direkt hinterlegt werden können.
-
Folgende Werte waren vor 2026.1 vorhanden und wurden wie in der Tabelle beschrieben automatisch migriert:
-
-
|
KI-Provider |
Alter Schlüsselwert |
Neuer Wert im Textfeld |
|---|---|---|
|
Mistral |
Mistral Large |
mistral-large-latest |
|
OpenAI |
GPT-4.1 |
gpt-4.1-2025-04-14 |
|
OpenAI |
GPT-4.1 mini |
gpt-4.1-mini-2025-04-14 |
|
OpenAI |
GPT-4o mini |
gpt-4o-mini-2024-07-18 |
|
OpenAI |
GPT-4o |
gpt-4o-2024-08-06 |
|
OpenAI |
GPT-4-Turbo |
gpt-4-turbo-2024-04-09 |
-
API-Key: Zugangsschlüssel zum verwendeten Modell
-
URL: verwendete Schnittstellen-URL
bis 26.4
-
Max. Tokens: Hier wird festgelegt, wie viele Token eine von der KI generierte Antwort maximal haben darf. Hinter dem Feld wird ein Fragezeichen mit dem folgenden Tooltip angezeigt:
-
Legt die maximale Anzahl an Token für die Ausgabe fest. Sollte der eingegebene Wert das Modell-Maximum überschreiten, wird automatisch die höchstmögliche Anzahl des gewählten Modells verwendet.
-
-
Deterministik: Hier kann eingestellt werden, wie unterschiedlich die Antworten der KI sein können. Dies kann je nach Kontext unterschiedlich sein, so will man z.B. bei Textvorschlägen mehr Unterscheidungen haben, wie bei einer Zusammenfassung.
Während man beispielsweise bei einer Zusammenfassung von Dokumenten der KI keine besonderen Gestaltungsspielräume geben möchte, so kann man die Deterministik so einstellen, dass die Zusammenfassung für jeden Aufruf sehr ähnlich formuliert wird. Andererseits möchte man bei Gratulationsmails nicht immer das selbe Zitat verwenden, weswegen hier sehr unterschiedliche Formulierungsvorschläge für eine persönliche Note Sinn machen.
ab 2026.4
-
Wichtiger Hinweis (Migration): Die Felder "Max. Tokens" und "Deterministik" wurden in die Eingabe-Verwaltung verschoben.
-
Deterministik deaktivieren: Einige KI-Modelle (z.B. Reasoning-Modelle oder GPT-5.2 Pro) unterstützen keine anpassbare Deterministik. Für diese Modelle steht nun ein neuer Schalter "Deterministik deaktivieren" zur Verfügung (Standardwert:
false). Wenn dieser aktiviert wird, wird die Deterministik beim Verbindungstest aufnullgesetzt und bei der Konfiguration in der Eingabe-Verwaltung ignoriert.
Logik basierend auf Provider-Auswahl
Je nach ausgewähltem Provider werden unterschiedliche Felder zu Pflichtfeldern:
-
Auswahl "Mistral":
-
Die Felder Modell & Version, API-Key und Url werden zu Pflichtfeldern.
-
-
Auswahl "OpenAI (oder OpenAI kompatible Provider)":
-
Die Felder Modell & Version, API-Key und Url werden zu Pflichtfeldern.
-
-
Auswahl "Azure":
-
Das Feld Modell & Version wird ausgeblendet und ist damit kein Pflichtfeld.
-
Die Felder API-Key und Url werden zu Pflichtfeldern.
-
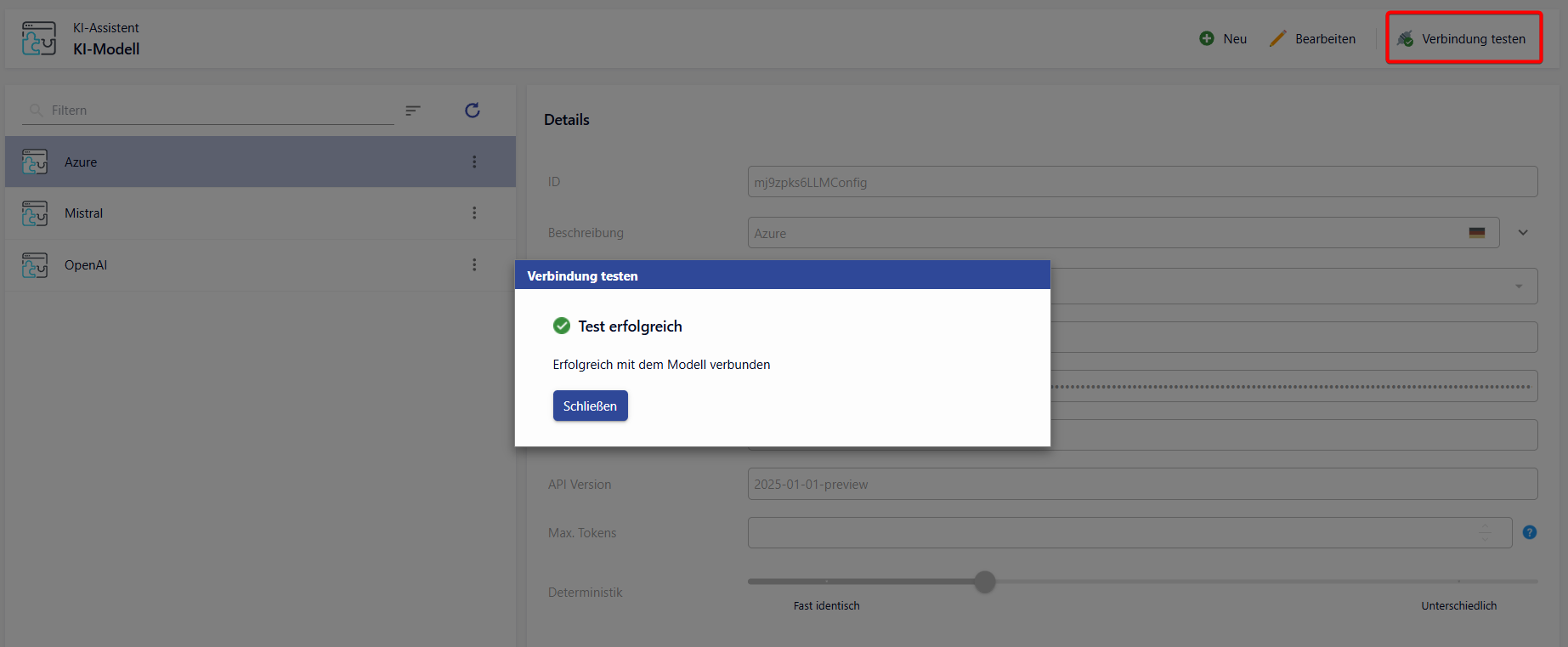
Button "Verbindung testen"
Mit dem Button "Verbindung testen" kann nur die gespeicherte Konfiguration getestet werden. Beim Klick auf den Button wird eine Anfrage an die KI gesendet ("Bist du erreichbar?").
-
Erfolgsfall: Bei einer erfolgreichen Antwort wird eine Erfolgsmeldung visualisiert.
-
Fehlerfall: Tritt ein Fehler auf (z.B. Service nicht erreichbar, Fehler bei der Rückgabe), wird die Fehlermeldung angezeigt und kann in die Zwischenablage kopiert werden.
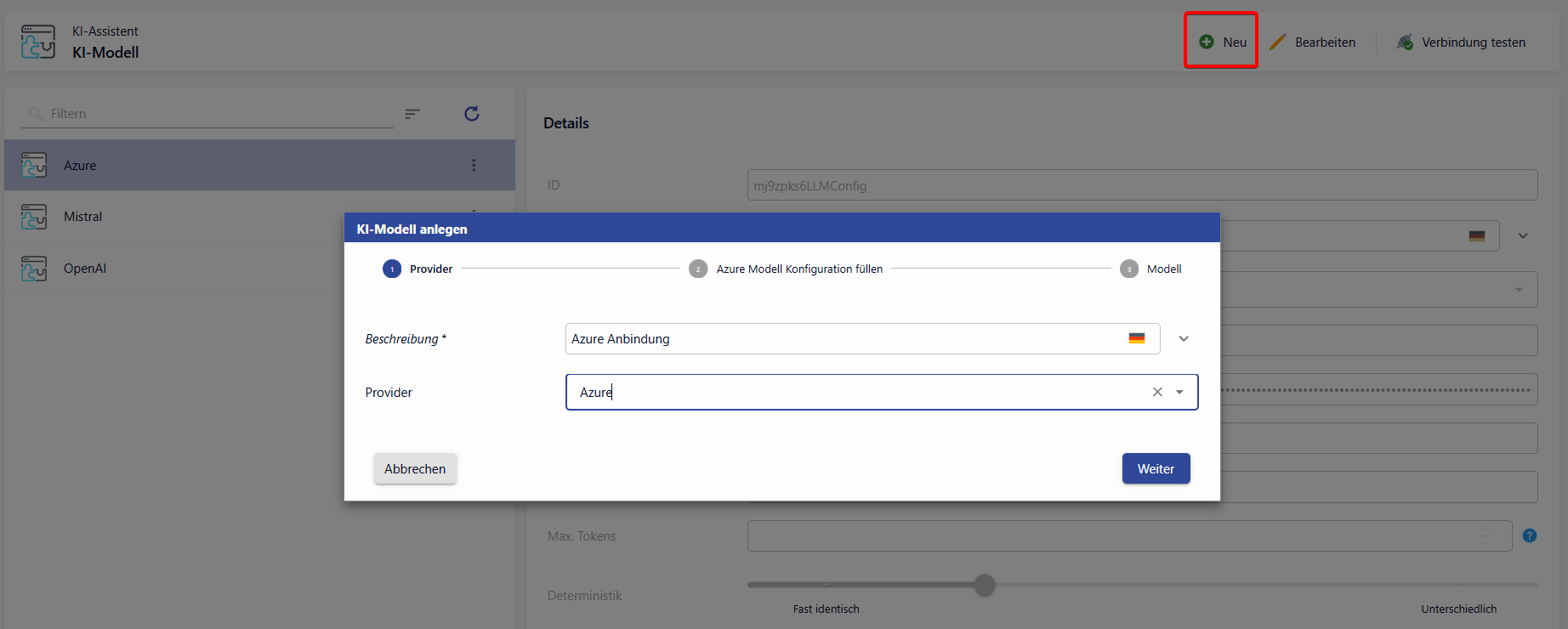
Wizard für die Neuanlage von KI-Modellen
Bei der Neuanlage eines KI-Modells wird ein Wizard aufgerufen.
-
Schritt: Benennung des KI-Modells und Auswahl des KI-Providers.
-
Schritt (optional bei Azure): Im Fall von Azure wird ein Zwischenschritt eingebaut, in dem der komplette Azure-Link eingefügt werden kann. Dies hat den Vorteil, dass im darauffolgenden Schritt alle Einzelheiten des Links (Url, Deployment, API-Version) automatisch in die einzelnen Felder eingefügt werden.
-
Schritt:
-
Azure: Hinterlegung des API-Keys. Wenn der vorherige Schritt übersprungen wurde, müssen hier alle Felder (Url, Deployment, API-Version, API-Key) manuell gefüllt werden.
-
OpenAI und Mistral: Im zweiten Schritt müssen der KI-Modellname und der API-Key eingefügt werden.
-